

新加坡网络安全局发布《AI系统安全指南》
责编:gltian |2024-10-21 16:46:12文/麻策律师
新加坡在人工智能领域的安全治理野望,属于路人皆知的存在。
继新加坡在2024年5月30日发布的《生成式人工智能的治理框架》,2024年9月 23日新加坡最高人民法院发布《关于法院用户使用生成式人工智能工具指南》之后,新加坡又双叒叕发布和AI安全有关的指南。
2024年10月15日,新加坡网络安全局 (CSA) 制定并一口气发布了 《AI 系统安全指南》及其配套指南——《AI 系统安全配套指南》,以帮助系统所有者在 AI 的整个生命周期内保护 AI。这两个指南将有助于保护 AI 系统免受供应链攻击等传统网络安全风险和对抗性机器学习等新风险的影响。

指南可以称作是网络协作的典型,本身并不属于法规规范,而是来自工业界和学术界的实用措施、安全控制和最佳实践,引用了 MITRE ATLAS 数据库和 OWASP 机器学习和生成式 AI 的 10 大资源。
新加坡认为,要获得 AI 的好处,用户必须确信 AI 将按设计运行,并且结果是安全可靠的。但是,除了安全风险之外,AI 系统还可能容易受到对抗性攻击,恶意行为者会故意操纵或欺骗 AI 系统。AI 的采用可能会给企业系统带来或加剧现有的网络安全风险。这可能会导致数据泄露或数据泄露等风险,或导致有害或不希望的模型结果。
因此,作为一项关键原则,AI 应该在设计上是安全的,并且与所有软件系统一样,应该是默认安全的。这将使系统所有者能够管理上游的安全风险。这将补充系统所有者为解决 AI 安全问题而可能采取的其他控制和缓解策略,以及公平性或透明度等其他随之而来的考虑因素,这些因素在此处未涉及。
谁应当看?
指南认为其面向的对象主要分为三类,一是负责监督⼈⼯智能系统实施⼈⼯智能的战略和运营⽅⾯的决策人员,即负责制定⼈⼯智能计划的愿景和⽬标、定义产品要求、分配资源、确保合规性以及评估⻛险和效益的人员,角色包括产品经理、项目经理。
其二,包括负责AI整个生命周期的实际应用开发的从业人员(即设计、开发和实施人工智能模型和解决方案),如人工智能/ML 开发人员、人工智能/ML 工程师、数据科学家。
最后,包括⽹络安全从业⼈员,即负责确保⼈⼯智能系统的安全性和完整性的人员,包括IT 安全从业人员、网络安全专家。
从⻛险评估开始
人工智能系统所有者应考虑从⻛险评估⼊⼿,重点关注⼈⼯智能系统的安全⻛险,其次,根据⻛险程度、影响和可⽤资源,确定应对⻛险的优先次序,再次确定并实施相关⾏动,确保⼈⼯智能系统的安全,最后评估残余⻛险,以减轻或接受⻛险。
1. 规划设计
要保持全员提高对AI安全风险的认识和能力,例如,LLM 安全事项、常见的人工智能弱点和攻击。建立合适的跨职能团队,确保从一开始就将安全、风险和合规性考虑在内。
AI 系统需要大量数据进行训练;有些还需要导入外部模型和库。如果保护不充分,AI 系统可能会受到供应链攻击的破坏,或者可能容易受到 AI 模型或底层 IT 基础设施中的漏洞的入侵或未经授权的访问。此外,如果云服务、数据中心运营或其他数字基础设施中断(例如通过拒绝服务攻击),组织和用户可能会失去访问和使用 AI 工具的能力,这反过来可能会使依赖 AI 工具的系统瘫痪。
2.进行安全风险评估
采用整体流程来模拟系统面临的威胁。制定/开发操作手册和人工智能事件处理程序,缩短补救时间,减少不必要步骤的资源浪费。
在实践中,需要有效区别传统网络风险和基于AI的特定风险。保护 AI 系统会带来传统 IT 系统中可能不熟悉的新挑战,除了经典的网络安全风险外,AI 本身还容易受到新型攻击,例如对抗性机器学习 (ML),这些攻击旨在扭曲模型的行为。
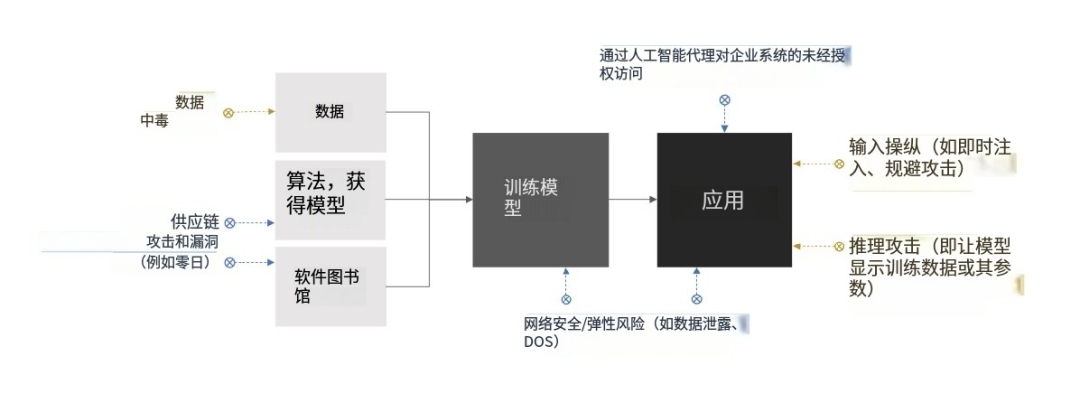
AI 与传统软件之间的根本区别在于,传统软件依赖于静态规则和显式编程,而 AI 使用机器学习和神经网络来自主学习和做出决策,而无需为每项任务提供详细说明。因此,组织应考虑比传统系统更频繁地进行风险评估,即使他们的风险评估方法通常基于现有的治理和政策。这些评估还可以通过持续监测和强大的反馈循环来补充。
3.生命周期合规
AI有五个关键阶段 – 规划和设计、开发、部署、运营和维护以及生命周期结束。与良好的网络安全实践一样,CSA 建议系统所有者采用生命周期方法来考虑安全风险。仅强化 AI 模型不足以确保全面防御 AI 相关威胁。AI 系统整个生命周期中涉及的所有利益相关者都应寻求更好地了解安全威胁及其对 AI 系统预期结果的潜在影响,以及需要做出哪些决策或权衡。
AI 生命周期表示设计 AI 解决方案以满足业务或运营需求的迭代过程。因此,系统所有者在交付 AI 解决方案时,可能会多次重新审视生命周期中的规划和设计、开发和部署步骤。
4.确保供应链安全
评估和监控整个系统生命周期的供应链安全。应用软件开发生命周期(SDLC)流程。使用软件开发工具检查不安全的编码实践。考虑在系统设计中实施零信任原则。在AI供应链端,确保数据、模型、编译器、软件库、开发工具和应用程序来自可信来源。使用自动数据发现工具识别各种环境中的敏感数据,包括数据库、数据湖和云存储。不受信任的第三方模型是从公共/私有资源库中获取的模型,其发布者的来源无法验证。
5. 训练数据安全
考虑是否需要使用 PII 或敏感数据来生成模型将引用的矢量数据库,例如在使用检索增强生成 (RAG) 时。考虑与使用敏感数据进行模型训练相关的权衡。企业在决定是否将敏感数据用于模型训练之前,不妨探索各种风险缓解措施,以确保非公开敏感数据的安全,例如匿名化和隐私增强技术。
6. 外部模型使用
对于 LLMs,提示工程最佳实践(如使用护栏和在单对加盐序列标记中包装指令)可作为进一步巩固模型的方法。对数据收集、数据存储、数据处理和数据使用以及代码和模型安全性进行数据安全控制。
7. 记录标识
了解人工智能相关资产的价值,包括模型、数据、提示、日志和评估,制定跟踪、验证、版本控制和保护资产的流程。建立数据和软件许可证管理流程。这包括记录数据、代码、测试用例和模型,包括任何更改和更改人。对于 PII 等敏感数据,在输入人工智能之前,应探索各种风险缓解措施,以确保非公开敏感数据的安全,如数据匿名化和隐私增强技术。
8.确保人工智能开发环境的安全
对应用程序接口、模型和数据、日志以及它们所处的环境实施适当的访问控制。根据最少特权原则,对开发环境进行基于规则和角色的访问控制。定期审查角色冲突或违反职责分工的情况,并应保留包括补救措施在内的文件。对于已离职的用户或不再需要访问权限的员工,应立即取消其访问权限。实施访问记录和监控。
9.建立事件管理程序
确保制定适当的事件响应、升级和补救计划。制定不同的事件响应计划,以应对不同类型的故障和可能与 DOS 混合的潜在攻击情景。实施取证支持,防止证据被删除。利用威胁猎取确定攻击的全部范围并调查归因。
10.发布人工智能系统
在创建新模型或数据时,计算并共享模型和数据集散列/签名,并更新相关文档,如模型卡。在可能的情况下,考虑使用对抗测试集来验证模型的稳健性。系统负责人和项目团队跟进安全测试/红队的结果,评估发现的漏洞的严重性,采取额外措施,如有必要,根据企业风险管理/网络安全政策,寻求相关实体(如首席信息安全官)的批准,以接受残余风险。
11.运营和维护
监控人工智能系统输入,监控和记录对系统的输入,如查询、提示和请求。适当的日志记录有助于合规、审计、调查和补救。人工智能系统所有者可考虑监控和验证输入提示、查询或应用程序接口请求,以防有人试图访问、修改或外泄组织视为机密的信息。如果可能,防止用户持续高频率地查询模型。