

微软安全大模型的应用架构
责编:gltian |2024-10-12 16:05:16微软有最全的安全产品,以云上为主,也就有了最好的数据。他们用了OpenAI的模型,最好的,团队,也基本没有哪个公司可比。
所以微软做了Security Copilot非常炫酷,上一篇已经介绍过了,可以参考
那么,微软是如何使用大模型的?本文作一分析。
本文共分四部分
一、大模型基本能力
二、大模型的缺陷
三、微软的应用架构
四、总结
01 大模型的基本能力
我们最常使用大模型的方法,是对话。另外,还有一种方法,是API调用,用于基于大模型的软件开发。
无论是对话,还是API调用,大模型的运作是一样的,就是根据一个请求,作出相关的响应,就这一个主要功能。其实这也是大模型的基本能力。
在API调用上,对这个功能再细化,有两个能力需要重点强调:
- 函数调用(Function Calling)
Function Calling(函数调用)是大模型与外部系统或API交互的能力。简单地理解,你有一些函数,用于处理问题。以前的做法,是在代码里写死,流程走到哪,调用哪个函数,使用什么参数。
用大模型不一样了,你可以把函数描述和要求给到大模型作为请求,大模型会根据你的要求,找到合适的函数,并填上适当的参数给你。
函数可以是多个,大模型会根据对话内容,自动选择合适的函数及参数。
2.Sql生成
Sql生成和函数调用类似。以前需要自己写Sql,现在不用了,你把数据库的描述和查询需求给它,述数据库结构和查询需求同时给到大模型,它可以生成一个Sql语句,这个功能实际有很多用法,不过深讨论。
02 大模型的缺陷
大模型的函数调用能力,用于对外部工具的调用,是个非常有价值的工具。毕竟,相对原来根据需求,一行一行写代码调用,现在只要说一句话,它就能调用哪个工具,并准确输入参数,这对软件是个巨大的进步。
但它有个致命的缺陷:大模型并没有临时记忆,就是每次请求,都需要完整地输入所有的函数描述。你没看错,是每一次。你跟大模型聊天,看上去大模型记住了你前边说过的话,实际上,是浏览器每一次都把前边所有的对话也发给了大模型,每一次调用,都要带上所有历史记录,而大模型本身并没有会话的概念,它什么都记不住。
这是个令人崩溃的事情,一来每次调用都是巨大的tokens消耗,费用巨大,性能非常差。二是针对大的系统,函数的描述是海量的,而大模型的输入又有长度限制,很可能prompt放不下。
针对这个问题,openai最初给的方案是微调。微调就是给出一系列指令,比如说A需求,调用FA函数,B需求,调用FB函数。这个方案显然降低了大模型的智能,比传统写代码确实强点,但大模型的智能显然是没用好。
最近,OpenAI和Claude又有了一个相对优化的解决方案,是Prompt caching.
Prompt caching是一种优化大型语言模型(LLMs)性能和效率的技术。这个概念相对较新,主要应用于需要频繁使用LLMs的场景。以下是对prompt caching的详细介绍:
概念定义:Prompt caching是指将常用的prompt及其对应的模型输出存储起来,以便在后续相同或相似的查询中快速检索和重用。
这个方案,减少了延迟,降低了成本,但仍然不算最终的理想方案。
这个问题,绕不过。看看微软是怎么解决的。
03 微软的应用架构
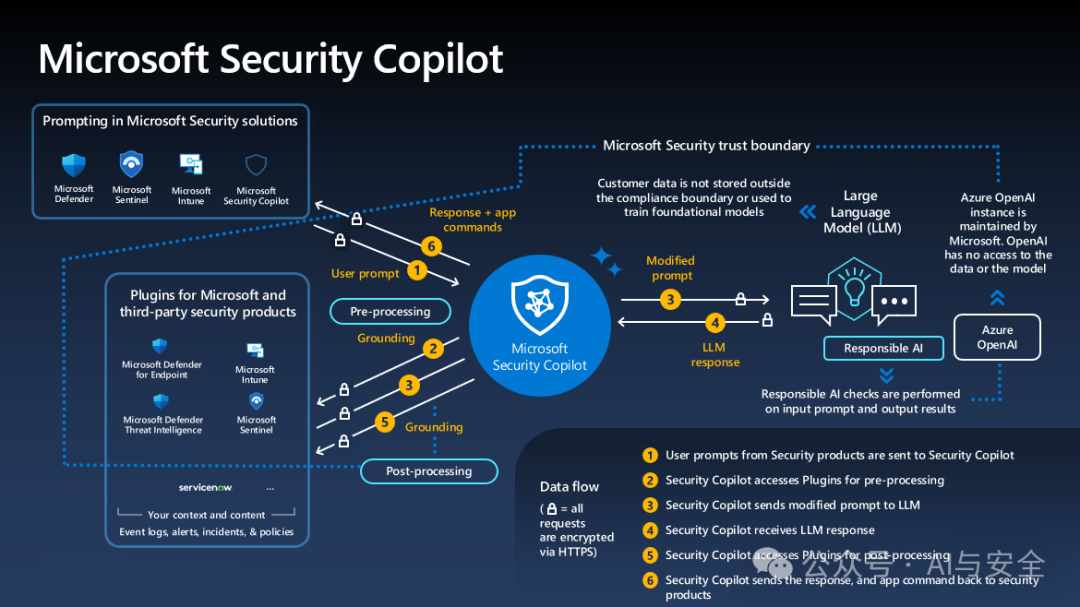
图一
上图是微软的应用架构,重点看copilot周边的六条数据流,黄色数字标识的部分。
- 用户输入提示
- Copilot根据用户提供,找到合适的插件(plugin,连接目标系统,取数据,函数表)
- Copilot根据插件取到的信息,重新修改prompt(增加信息),送给大模型
- 大模型根据要求,针对Copilot的请示返回结果
- Copilot把大模型的返回转给插件,作后处理,比如进一步的数据处理,函数调用要求等
- Copilot 将插件处理的结果,返回给应用,包括响应,应用命令等,由具体的安全进行处理,再将结果返回给用户。
这里边,比较关键的点有两个,一个是插件(plugin),一个是Copilot的插件选择(路由能力)
1.插件(plugin)的原理
它通过标准接口与copilot对接,可与外部数据进行交互。按,每个安全产品对应一个插件,可以获取相关数据。
2.路由
如何根据用户的请求(自然语言)找到合适的插件?微软没有明确说明。但这个功能,如果用大语言模型实现是非常容易的。两个方法都可以,一是在进行步骤3之前先调用一下大模型(这与图示不符),还有一个办法是在Copilot里再放一个小一点的模型。微软用了openai的模型,但也反复强调自身的模型训练,我认为后一种可能性更大。这个方法一般称为意图识别。当然,看花容易养花难,理论上好实现,和实际上实现好,还是有很大的差距。
CrowdStrike的Charlotte AI也非常强调路由能力,说的也是这个意思。
04 总结
大模型在近两年的发展中,表现出无比巨大的能力,但仅有大模型是不够的,结合大模型,做必要的外围开发,形成Agent,具备理解用户,挖掘分析数据,外部环境感知和工具调用能力,才是应用的完整方案。客户需要的不仅仅是通识问答,而是结合客户自身情况的完整答案,这个关键在于数据获取能力。
微软的Security Copilot就是个非常完整的Agent方案。
如果再具体一点,它就是个RAG(检索增强生成)方案。目前的方案已经表现的很好,相信随着大模型技术的发展,agent能力更多的由大模型承载,未来会有更强的能力。