

CrowdStrike导致全球性IT基础设施中断事件分析报告
责编:gltian |2024-07-22 10:58:54北京时间2024年7月19日中午开始,CrowdStrike问题更新导致全球Windows大面积蓝屏死机,致使航班停飞、火车晚点、银行异常、巴黎奥运服务受影响等,全球至少二十多个国家受到波及。
基于奇安信的独有数据视野,我们估计国内的CrowdStrike软件装机量在万级,相关单位数在百级,用户主要集中在北上广深等发达地区。受影响的主要是外企、外企在华分支机构及合资企业,大量这类机构中招,有反馈某个在华外企大量终端中的40%崩溃。
01 CrowdStrike公司及产品概况
CrowdStrike公司成立于2011年,由两位传统杀毒软件McAfee的高管创立,团队成员主要来自信息安全产业,如微软和亚马逊等。该公司是全球知名的下一代终端安全厂商,其核心产品包括基于云的Falcon平台及其多个模块,这些模块涵盖了端点保护、威胁情报、IT资产管理和恶意软件搜索等多个领域。目前市值超800亿美元,仅次于最大的网络安全公司Palo Alto Networks。
Falcon平台是CrowdStrike的核心产品,它是一个完全基于云端部署的SaaS模型,能够提供实时的攻击指标、威胁情报和不断进化的对手手法技术。该平台通过一个轻量级的代理架构实现快速且可扩展的部署,并提供高级别的保护和性能。此外,Falcon还集成了多种功能,如文件完整性监控、云安全、身份保护等。
CrowdStrike目前的客户数超24000个,覆盖了大部分全球500强企业,导致本次事故的就是其Falcon平台的核心组件驱动程序部分的功能。
02 IT服务中断情况
北京时间2024年7月19日周五下午2点多开始,全球大量Windows用户在社交媒体上晒出电脑蓝屏画面,出现了大量 Windows电脑崩溃、显示蓝屏死机、无法重新启动的案例。
由于事件发生时亚太地区在白天,美欧在夜晚,初期社交媒体上的反馈主要集中在亚太地区,主要是日本、澳大利亚。随着时间的进展,欧美用户也大量出现服务中断反馈。大量的机场、医院、媒体与银行由于系统的崩溃,导致服务中断,数以万计的航班延误取消,有些医院不得不转移病人,很多受影响企业的不得不提前放假。
事件还影响到了微软的云服务,主要应该是微软云服务上运行了大量的基于Windows系统的应用程序实例,其中部分安装了CrowdStrike的软件,所以连带着这些虚拟机也崩溃。当然,也可能有部分原因在于微软的管理云的应用系统也受到了CrowdStrike的影响。
在国内,“微软蓝屏”迅速登顶微博热搜,成为热议话题。随后,蓝屏问题被确认与CrowdStrike的软件更新有关,导致Windows用户出现了蓝屏现象。
CrowdStrike于7月19日下午发布相关通知承认了这一问题,并承诺将在45分钟后修复。
CrowdStrike本次IT系统中断事件的影响一定会被记入史册,与2017年的WannaCry勒索蠕虫事件可相提并论,所幸由于安全软件生态一定程度的隔离,中国所受的影响不大。
03 软件系统影响面
Falcon sensor for Windows version 7.11在线时间在北京时间7月19日中午12点09分到13点27分之间,下载了问题更新的系统会遭遇崩溃。
基于奇安信的独有数据视野,我们估计国内的CrowdStrike软件装机量在万级,相关单位数在百级,用户主要集中在北上广深等发达地区。受影响的主要是外企、外企在华分支机构及合资企业,大量这类机构中招,有反馈某个在华外企大量终端中的40%崩溃。
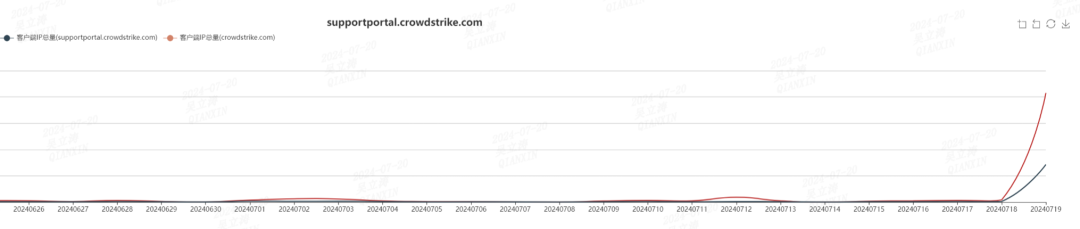
奇安信网络研究院对于CrowdStrike相关网站的访问监测显示,7月19日国内对于CrowdStrike支持网站的访问量出现了上百倍的增长,可见国内对此事件的关注度与处置力度也很高:
至于国内的其他类型单位,特别是党政央企,大型的民企公司,使用量极少。奇安信收到的相关应急响应需求很少,此次事件对国内的政府、央企及绝大部分的大型民企影响不大。
以当前Falcon软件的安装量,初步估计导致数以百万到千万计的Windows系统不可用,由于问题导致电脑只要启动就会蓝屏崩溃,因此没有自动化的措施可以执行批量集中修复,只能一台台手工操作解决问题,所以恢复过程会非常消耗时间与精力,估计完全恢复需要的时间将以周计。
04 技术细节相关的讨论
Falcon是安全软件,有其特殊性,需要获取操作系统底层权限来更好地实现保护能力,所以组件很多以驱动程序形态出现。这回导致系统崩溃的CSAgent.sys是CrowdStrike客户端的一个核心的驱动,驱动程序由于工作在内核态一旦执行上出现问题,就直接会导致操作系统不可用,启动时加载驱动直接蓝屏,这是它跟一般工作在应用层的应用程序是不一样的地方。
按CrowdStrike给出的解释,程序在增加处理新观察到的利用命名管道进行C&C通信的恶意代码活动时,更新相应的配置文件(“C-00000291-”开头的文件)触发了一个代码中的逻辑错误,在内核态形成非法内存访问触发操作Windows系统蓝屏。因此,导致问题的更新应该被视为某种“规则”的更新,而不是直接驱动程序本身,这也就可能解释了数据的下发如此的快速而“随意”,但依旧无法解释如此能导致明显危害的更新如何通过了发布前的测试环节。
05 解决方案
对于遇到此问题的用户,可以尝试以下措施来临时修复使系统可用:
1. 使用安全模式或恢复模式进入操作系统。
2. 进入 C:\\\\Windows\\\\System32\\\\drivers\\\\CrowdStrike 目录。
3. 找到所有匹配“C-00000291*.sys”的文件,并将其删除。
4. 正常启动主机。
或者直接重命名以下文件夹:
“C:\\\\Windows\\\\system32\\\\drivers\\\\CrowdStrike
临时修复措施很简单,但确实比较耗人工,需要一台一台的机器进入安全模式,然后把相关的文件删掉或改名,没什么特别的专用那个工具能集中批量地实现修复。
机器可以正常启动以后,如果还要继续使用CrowdStrike,更新到软件的最新版本,当前的版本已经修复。
06 事件的启示与建议
此次事件暴露出了CrowdStrike公司在产品开发测试发布环节中存在严重问题,存在质量缺陷的软件通过了测试,以看起来并没有灰度机制的方式被推送出来,直接导致了数以百万计的系统不可用。作为一个国际主流的大安全厂商,会出现这样的低级错误,这是整个事件中最不可思议的地方。
目前,主要有两种阴谋论的说法浮出水面,引起了人们的热烈讨论。
第一种说法认为,这起事件可能是美国政府进行的一种压力测试,目的是为了检验在遭受网络战攻击时的社会现象和应急恢复能力。然而,对于这一说法,有人认为其代价过于巨大。据估计,此次事件造成的直接和间接损失高达数十亿美元。尽管如此,仍有部分人坚持认为,这与历史上的某些事件相似,例如911恐怖袭击,他们认为这可能是政府的某种策略。
第二种说法则指向了CrowdStrike公司,认为有黑客入侵了该公司,并修改发布了恶意代码,导致了此次电脑崩溃事件。对于这一说法,普遍认为可能性相对较大。尽管CrowdStrike公司否认了遭受网络攻击的说法,但考虑到公司可能出于维护形象的考虑,这种否认也是可以理解的。然而,如果这一说法属实,公司将不得不面对可能的诉讼和赔偿问题。值得注意的是,目前还没有组织或个人宣称对此次事件负责。
在这两种说法中,尽管各有其支持者,但真相究竟如何,目前尚无定论。
其实终端软件安全厂商由于自己的开发运营能力问题搞出破坏客户系统的事件绝不新鲜,大多影响范围较小而不被公众所感知。2010年当时的McAfee就因为发布了错误的病毒定义,删除了Windows XP的系统文件而导致系统反复重启不可用。巧合的是当时McAfee的CEO就是现在CrowdStrike的CEO,可以说是传统艺能。因此,运营错误导致问题的可能性还是远高于阴谋论。
抛开阴谋论不提,一次软件更新引发全球 IT 事故,提醒了业界和广大用户,即使是非常成熟的技术平台也可能遭遇意外故障,再次凸显了“零事故”保障(业务不中断、数据不出事、合规不踩线)的重要性和必要性。
此次微软蓝屏,导致全球大量主机无法使用,包括终端和一部分服务器主机,对全球航空、金融等重要业务产生重大影响,大量重要政府企业无法对外提供服务,再回想2017年的永恒之蓝勒索病毒,同样导致了全球大量主机无法使用,大量政府企业无法提供服务。说明网络安全行业,已经和水电煤气一样,就是整个社会的关键基础设施行业,无论是没有防住网络攻击,还是升级更新出现问题,都会导致重大的社会影响。
因此,网络安全行业,真正要追求的目标是重要环境“零事故“,零事故的第一个标准就是“业务不中断”,从奇安信参与的2017年永恒之蓝的应急处理,和2022年北京冬奥的“零事故”安全保障,客户没有出现过勒索和蓝屏,核心业务都没有受到中断影响。
零事故的核心是对安全的持续投入和重视,是一个体系化建设工程,如果没有足够多、足够长时间的投入,”零事故“目标就无从谈起。对客户来说,应该以”零事故“为标准,做好业务弹性规划,以随时应对勒索软件攻击、员工失误或意外 IT 故障的威胁。
综上可见,业务稳定和网络安全不仅是技术问题,更是管理和战略问题,需全面综合考虑各种因素,主要体现在以下几点:
☞对于安全厂商
•首先是把好质量关。正所谓“能力越大责任也越大”,涉及系统稳定性的软件厂商需要对自己的软件有更严格的质量管理。否则,这种意外故障导致的业务连续性问题比恶意的网络攻击还要大。
•其次是做好升级策略。在产品升级时,要控制影响范围,俗称“爆炸半径”,掌控好升级策略,确保灰度升级,控制放量节奏。逐步测试,逐步增加覆盖。
•最后是态度需要积极主动。在出现事故时,平台厂商和安全厂商,都需要本着客户至上原则,最短时间给出客户相应的解决方案,并积极与公众沟通,避免因为信息差等导致的恐慌。
☞对于安全产品使用者
•选择有实力有信用背书的安全厂商,尤其基于当前复杂的国际环境,优先国内的能力厂商。
•在部署终端安全软件,要对资产做好分类,分级,对于关键资产设置单独的管理单元或分组,并设置灰度或延迟更新的策略。
☞对于国家相关主管机构
•持续推进国产化,安全软件工具平台与操作系统一样有特殊的影响和意义,必须确保自主可控。
•使用面巨大的软件应该作为关基一样的重点关注目标,鼓励国产化操作系统及流行软件的漏洞挖掘及风险消除的行动。
•进一步加强关键基础信息系统的保护,切实执行相关的法规,落实相应的能力建设。
参考
Technical Details on Today’s Outage
https://www.crowdstrike.com/blog/technical-details-on-todays-outage/
Global IT chaos persists as Crowdstrike boss admits outage could take time to fix
https://www.bbc.com/news/live/cnk4jdwp49et
来源:奇安信 CERT