

Lua程序逆向之为Luac编写IDA Pro文件加载器
责编:gltian |2018-08-01 10:34:11距离上一次讲Lua程序逆向已经有一段时间了,这一次我们书接上回,继续开启Lua程序逆向系列之旅。
在软件逆向工程实践中,为第三方文件编写文件格式分析器与指令反汇编器是一种常见的场景。这一篇的主要目的是,讲解如何为IDA Pro编写Luac的文件加载器,一方面强化对二进制文件格式的理解;另一方面,通过对IDA Pro进行扩展的插件式开发,更深入的领会IDA Pro的设计思想,以及掌握更多的高级使用方法。
IDA Pro提供了抽象的文件加载器与处理器模块概念。文件加载器与程序运行时的动态加载概念类似,将文件中的代码与数据,按照一定的逻辑方式进行排列与显示,文件加载器在设计时,会优先选择与文件二进制本身相关的数据结构进入载入,比如Windows、LInux、macOS上的二进制PE、ELF、Mach-O文件,它们都有数据、常量、代码段的概念,IDA Pro允许将这些二进制的不同的数据,加载到不同类型的段里面。
文件加载器的工作就是:分析文件的基本格式;解析文件的段层次结构,将需要用到的数据与代码加载到IDA Pro当中;区分与构建二进制中的数据与代码在段中的位置;创建函数,变量,建立交叉引用辅助用户进行分析等。当然,最后一项工作也可由处理器模块完成。
二进制文件加载器架构
IDA Pro没有详细的文档描述好何为二进制开发文件加载器,最有效的学习途径是阅读IDA Pro程序中自带的开源的文件加载器模块代码。
IDA Pro软件在升级着,版本的变化可能会也带来文件加载器开发接口的变化,本篇写作时,对应的IDA Pro版本为国内众所周知的IDA Pro版本7.0,实验环境为macOS 10.12平台。IDA Pro支持使用C/C++/idc/Python等多种语言编写文件加载器。这里选择使用Python,一方面基于语言的跨平台性,再者,IDA Pro软件的加载器目录(macOS平台):/Applications/IDAPro7.0/ida.app/Contents/MacOS/loaders中,有着可以参考的代码。理论上,本节编写的Luac文件加载器,放到Windows等其他平台上,不需要进行任何的修改,也可以很好的工作。
本次参考使用到的代码是uimage.py模块,这个不到200行的Python脚本是一个完整的U-Boot镜像加载器,完整的展示了二进制文件加载器的编写流程,是不错的参考资料。
文件加载器的架构比较简单,只需要在py文件中提供两个回调文法即可。分别是accept_file()与load_file()。accept_file()负责检查二进制文件的合法性,解析结果正常则返回二进制文件的格式化描述信息,该信息会显示在IDA Pro加载二进制文件时的对话框中,供用户进行选择。accept_file()的声明如下:
def accept_file(li, filename):
"""
Check if the file is of supported format
@param li: a file-like object which can be used to access the input data
@param filename: name of the file, if it is an archive member name then the actual file doesn't exist
@return: 0 - no more supported formats
string "name" - format name to display in the chooser dialog
dictionary { 'format': "name", 'options': integer }
options: should be 1, possibly ORed with ACCEPT_FIRST (0x8000)
to indicate preferred format
"""accept_file()判断文件合法后,再由load_file()执行二进制的具体加载工作,这些工作包含设置处理器类型、将文件内容映射到idb数据库中、创建数据与代码段、创建与应用特定数据结构、添加入口点等。accept_file()的声明如下:
def load_file(li, neflags, format):
"""
Load the file into database
@param li: a file-like object which can be used to access the input data
@param neflags: options selected by the user, see loader.hpp
@return: 0-failure, 1-ok
"""
Luac文件加载器的实现
下面来动手实现基于Lua 5.2生成的二进制Luac文件的加载器。将uimage.py模块复制一份改名为loac_loader.py。并修改accept_file()代码如下:
def accept_file(li, n):
"""
Check if the file is of supported format
@param li: a file-like object which can be used to access the input data
@param n : format number. The function will be called with incrementing
number until it returns zero
@return: 0 - no more supported formats
string "name" - format name to display in the chooser dialog
dictionary { 'format': "name", 'options': integer }
options: should be 1, possibly ORed with ACCEPT_FIRST (0x8000)
to indicate preferred format
"""
header = read_struct(li, global_header)
# check the signature
if header.signature == LUA_SIGNATURE and 0x52 == header.version:
global size_Instruction
global size_lua_Number
size_Instruction = header.size_Instruction
size_lua_Number = header.size_lua_Number
DEBUG_PRINT('signature:%x' % header.signature)
DEBUG_PRINT('version:%x' % header.version)
DEBUG_PRINT('format:%x' % header.format)
DEBUG_PRINT('endian:%x' % header.endian)
DEBUG_PRINT('size_int:%x' % header.size_int)
DEBUG_PRINT('size_Instruction:%x' % header.size_Instruction)
DEBUG_PRINT('size_lua_Number:%x' % header.size_lua_Number)
DEBUG_PRINT('lua_num_valid:%x' % header.lua_num_valid)
if header.size_Instruction != 4:
return 0
#if header.size_lua_Number != 8:
# return 0
return FormatName
# unrecognized format
return 0read_struct()目的是借助ctype模块读取文件开始的内容,到定义的global_header类型的数据结构中去,它的第一个参数li是一个类似于文件对象的参数,可以理解它类似于C语言fopen返回的文件描述符,也可以将其理解为指向文件数据头部的指针。
global_header数据结构来自于之前Luac.bt文件中的C语言声明,它的定义如下:
class global_header(ctypes.Structure):
_pack_ = 1
_fields_ = [
("signature", uint32_t),
("version", uint8_t),
("format", uint8_t),
("endian", uint8_t),
("size_int", uint8_t),
("size_size_t", uint8_t),
("size_Instruction", uint8_t),
("size_lua_Number", uint8_t),
("lua_num_valid", uint8_t),
("luac_tail", uint8_t * 6),
]定义的class继承自ctypes.Structure,可以编写类似于C语言的结构体定义来描述数据结构,这种方式比起直接struct.unpack方式来读取要方便与优雅得多。
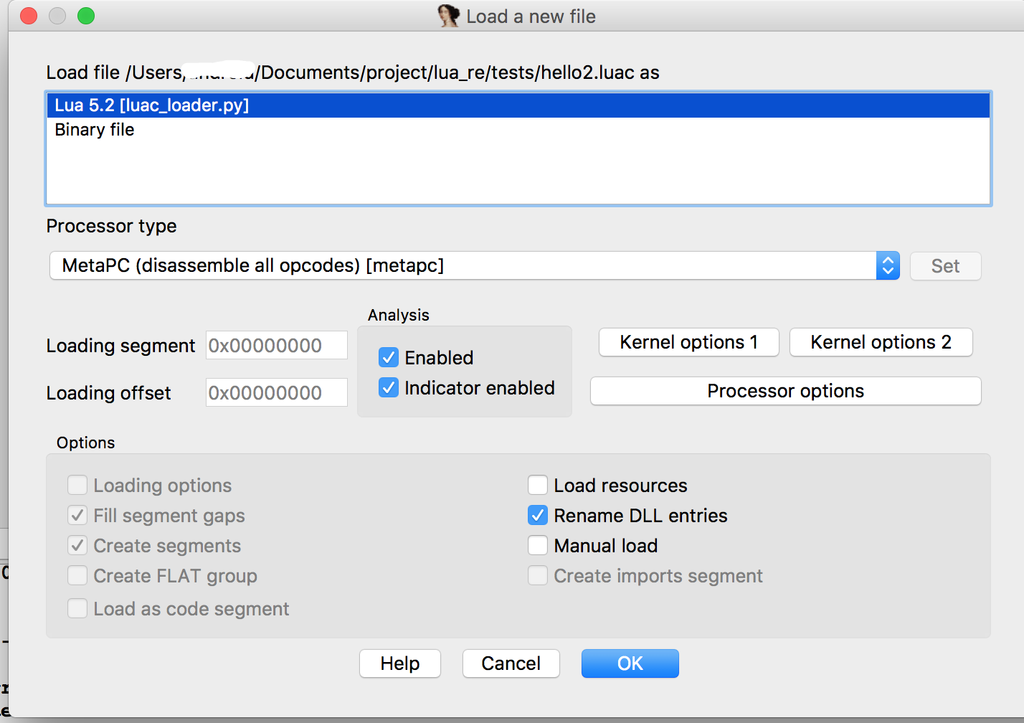
当读取到一个完整的global_header后,需要判断它的signature字段与version字段是否匹配Lua 5.2版本,如果匹配,还需要判断size_Instruction字段,即指令所占的字节大小,通常它的值应该为4。所有的这些条件都满足后,则说明该文件可能是一个正确版本的Luac二进制,那么直接返回格式化名称FormatName。它的内容为:Lua 5.2。将luac_loader.py放入IDA Pro的loaders目录下,将Hello2.luac文件拖入到IDA Pro的运行主窗口,此时会弹出如图所示的对话框:
接着是load_file(),它的代码如下:
def load_file(li, neflags, format):
"""
Load the file into database
@param li: a file-like object which can be used to access the input data
@param neflags: options selected by the user, see loader.hpp
@return: 0-failure, 1-ok
"""
if format.startswith(FormatName):
global_header_size = ctypes.sizeof(global_header)
li.seek(global_header_size)
header = read_struct(li, proto_header)
DEBUG_PRINT('linedefined:%x' % header.linedefined)
DEBUG_PRINT('lastlinedefined:%x' % header.lastlinedefined)
DEBUG_PRINT('numparams:%x' % header.numparams)
DEBUG_PRINT('is_vararg:%x' % header.is_vararg)
DEBUG_PRINT('maxstacksize:%x' % header.maxstacksize)
idaapi.set_processor_type("Luac", SETPROC_ALL|SETPROC_FATAL)
proto = Proto(li, global_header_size, "0") #function level 0
add_segm(0, 0, global_header_size, "header", 'HEADER')
add_structs()
MakeStruct(0, "GlobalHeader")
global funcs
global consts
global strs
for func in funcs:
#add funcheader_xx segment.
add_segm(0, func[3], func[3] + ctypes.sizeof(proto_header), func[4], 'CONST')
MakeStruct(func[3], "ProtoHeader")
# add func_xx_codesize segment.
add_segm(0, func[1] - 4, func[1], func[0] + "_codesize", 'CONST')
MakeDword(func[1]-4)
set_name(func[1]-4, func[0] + "_codesize")
# add func_xx segment.
add_segm(0, func[1], func[2], func[0], 'CODE')
#add_func(func[1], func[2])
for const in consts:
# add const_xx_size segment.
add_segm(0, const[1]-4, const[1], const[0] + "_size", 'CONST')
MakeDword(const[1]-4)
set_name(const[1]-4, const[0] + "_size")
# add const_xx segment.
add_segm(0, const[1], const[2], const[0], 'CONST')
for str in strs:
# add const strings.
idc.create_strlit(str[1], str[2])
li.file2base(0, 0, li.size(), 0) #map all data
mainfunc_addr = proto.code_off + 4
print("main func addr:%x" % mainfunc_addr)
add_entry(mainfunc_addr, mainfunc_addr, 'func_0', 1)
DEBUG_PRINT("Load Lua bytecode OK.")
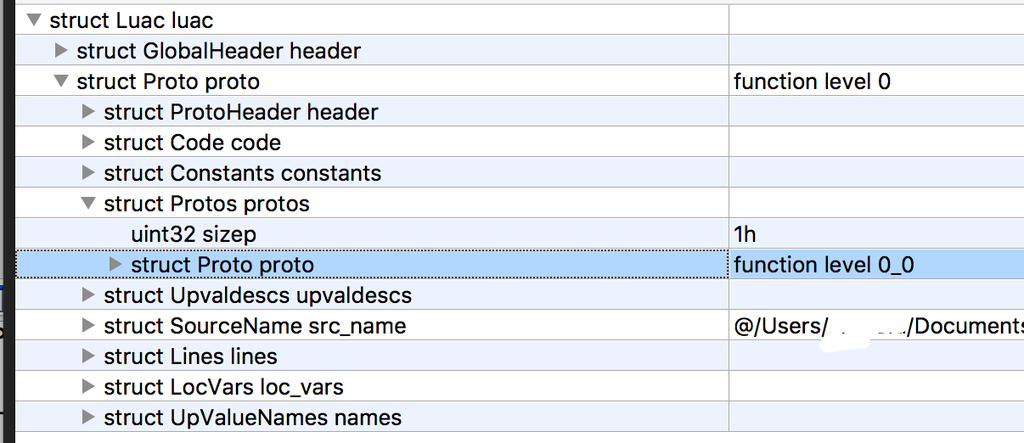
return 1当format参数是accept_file()返回的FormatName是,说明是合法的Luac,正常进入了文件内容加载阶段。这时候按照之前分析Luac格式,使用li.seek()跳过global_header,解析proto_header结构。这是最“顶层的”Proto结构的头部,描述了function level 0包含多少个子Proto及其其他字段信息。回顾下前面的知识,Proto的可视化结构如图所示:
Proto类型的实现与读取相对会麻烦一些,代码如下:
funcs = []
consts = []
strs = []
class Proto:
def __init__(self, li, off, level):
self.level = level
DEBUG_PRINT("level: %s\n" % self.level)
off_ = off
li.seek(off)
self.header = read_struct(li, proto_header)
off += ctypes.sizeof(proto_header)
self.code_off = off
self.code = Code(li, off)
funcs.append(get_func_area(level, off + 4, off + self.code.size(), off_))
off = off + self.code.size()
self.constants = Constants(li, off)
consts.append(get_consts_area(level, off + 4, off + self.constants.size()))
off = off + self.constants.size()
DEBUG_PRINT("protos off:%x\n" % off)
self.protos = Protos(li, off, level)
off = off + self.protos.size()
self.upvaldecs = Upvaldescs(li, off)
off = off + self.upvaldecs.size()
self.src_name = SourceName(li, off)
off = off + self.src_name.size()
self.lines = Lines(li, off)
off = off + self.lines.size()
self.loc_vars = LocVars(li, off)
off = off + self.loc_vars.size()
self.upval_names = UpValueNames(li, off)
off = off + self.upval_names.size()
self.sz = off - off_
def size(self):
return self.sz函数、常量、字符串这些信息在解析后我们全局进行保存,目的是后面在创建各种类型的数据段时需要用到。Protos、Constants、LocVars、UpValueNames这些数据结构的定义,由于篇幅原因就不帖出来了,具体的实现代码可以在文末的代码地址处获取。
接着有一条比较重要的调用:
idaapi.set_processor_type("Luac", SETPROC_ALL|SETPROC_FATAL)idaapi.set_processor_type()用来设置处理器模块,这里使用的”Luac”是我事先编写好的处理器模块,将会在以后进行讲解,初期开发时,可以将其指定为IDA Pro中提供的其他样例处理器模块辅助开发加载器。
解析完Luac,集齐这些数据后,就可以使用IDA Pro提供的add_segm()接口,在idb数据库中创建段了。add_segm()的定义位于ida_segment.py中,如下所示:
def add_segm(*args):
"""
add_segm(para, start, end, name, sclass, flags=0) -> bool
"""
return _ida_segment.add_segm(*args)第一个参数通常为0;start与end指明了数据的起始与结束地址;name为段的名称;sclass为段的类别,类别可以是HEADER表示文件头,CONST表示是常量数据,CODE表示是代码段,DATA表示是数据段。 如下的代码即会创建一个HEADER类别的段:
add_segm(0, 0, global_header_size, "header", 'HEADER')创建完段后,我们还想将这个段的内容应用上global_header结构体声明,让IDA Pro可以更加直观显示字段的描述与数值。这个时候,就需要将global_header结构体的声明先加入到IDA Pro中去。三种方法可以实现:一是导入事先声明好相关结构体的til文件;二是在内存中制作til,导入C语言的结构体描述,然后会在内存中创建til;最后一种是使用脚本一行行导入结体体声明。最终,在相应的数据位置应用结构体信息即可。第一种方法这里不讲,因为没有事先做好til,第二种方法可以使用代码来自动化完成,首先使用new_til()在内存中创建til,然后使用parse_decls()与doStruct()接口解析C语言结构生成til结构体信息,最后一种其实最方便,这里推荐一下,可以事先在IDA Pro中手动导入C声明,然后执行File->Product file->Dump datebase to IDC file…,执行后会生成所有IDA Pro操作过的idc脚本,其中包括导入与创建、应用数据结构体的部分。将这一段代码引入到Python中即可。这里add_structs()的代码片断如下:
def add_structs():
begin_type_updating(UTP_STRUCT)
AddStrucEx(-1, "GlobalHeader", 0)
AddStrucEx(-1, "ProtoHeader", 0)
id = GetStrucIdByName("GlobalHeader")
AddStrucMember(id, "signature", 0, 0x000400, -1, 4)
AddStrucMember(id, "version", 0X4, 0x000400, -1, 1)
AddStrucMember(id, "format", 0X5, 0x000400, -1, 1)
AddStrucMember(id, "endian", 0X6, 0x000400, -1, 1)
......
SetType(get_member_id(id, 0x0), "unsigned int")
SetType(get_member_id(id, 0x4), "unsigned int")
SetType(get_member_id(id, 0x8), "unsigned __int8")
SetType(get_member_id(id, 0x9), "unsigned __int8")
SetType(get_member_id(id, 0xA), "unsigned __int8")
end_type_updating(UTP_STRUCT)
set_inf_attr(INF_LOW_OFF, 0x20)
set_inf_attr(INF_HIGH_OFF, 0x22A)添加了结构体后,执行MakeStruct(0, “GlobalHeader”)即可将起始的HEADER数据段应好了GlobalHeader结体体信息。如图所示:
接着如法炮制,加载其他的段,加载完成后,执行如下的命令完成数据的映射工作:
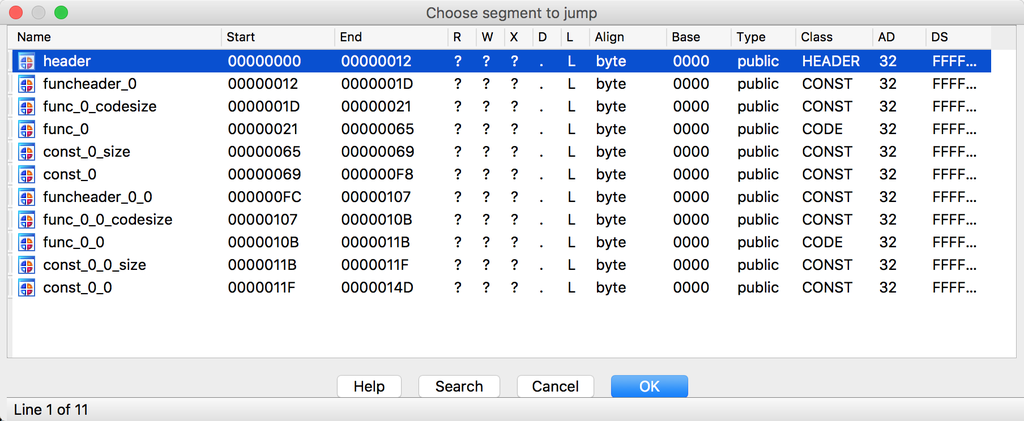
li.file2base(0, 0, li.size(), 0)最后,是调用add_entry()设置程序的入口点。完成后,加载器的工作基本就完成了。加载器完成Luac加载后,可以在IDA Pro中查看它的段结构信息如下:
后面,将会是处理器模块负责创建函数、数据、交叉引用、反汇编等工作。
完整的luac_loader.py文件可以在这里找到:https://github.com/feicong/lua_re。
Lua程序逆向系列的故事仍然在继续着,To be continued…