

分布式文件系统之MooseFS----管理优化
责编:admin |2015-01-14 14:40:59一、高级功能
1、副本
副本,在MFS中也被称为目标(Goal),它是指文件被复制的份数,设定目标值后可以通过mfsgetgoal命令来证实,也可以通过mfssetgoal命令来改变设定。
[root@mfs-client ~]# cd /mfsdata/
[root@mfs-client mfsdata]# dd if=/dev/zero of=/mfsdata/test.file bs=1M count=200
200+0 records in
200+0 records out
209715200 bytes (210 MB) copied, 9.1094 s, 23.0 MB/s
[root@mfs-client mfsdata]# mfsgetgoal test.file
test.file: 1
[root@mfs-client mfsdata]# mfssetgoal 3 test.file
test.file: 3
[root@mfs-client mfsdata]# mfsgetgoal test.file
test.file: 3
补充:
用mfsgetgoal –r和mfssetgoal –r同样的操作可以对整个树形目录递归操作
[root@mfs-client mfsdata]# mkdir dir/dir1/dir2/dir3 -p
[root@mfs-client mfsdata]# touch dir/file1
[root@mfs-client mfsdata]# touch dir/dir1/file2
[root@mfs-client mfsdata]# touch dir/dir1/dir2/file3
[root@mfs-client mfsdata]# mfsgetgoal -r dir
dir:
files with goal 1 : 3
directories with goal 1 : 4
[root@mfs-client mfsdata]# mfssetgoal -r 3 dir
dir:
inodes with goal changed: 7
inodes with goal not changed: 0
inodes with permission denied: 0
实际的拷贝份数可以通过mfscheckfile 和 mfsfileinfo 命令来证实,例如:
[root@mfs-client mfsdata]# mfscheckfile test.file
test.file:
chunks with 1 copy: 4
[root@mfs-client mfsdata]# mfsfileinfo test.file
test.file:
chunk 0: 00000000000000D2_00000001 / (id:210 ver:1)
copy 1: 172.16.100.6:9422
chunk 1: 00000000000000D3_00000001 / (id:211 ver:1)
copy 1: 172.16.100.7:9422
chunk 2: 00000000000000D4_00000001 / (id:212 ver:1)
copy 1: 172.16.100.6:9422
chunk 3: 00000000000000D5_00000001 / (id:213 ver:1)
copy 1: 172.16.100.7:9422
需要注意的是,一个包含数据的零长度的文件,尽管没有设置为非零的目标(the non-zero goal),但是在使用命令查询时将返回一个空值
[root@mfs-client mfsdata]# touch a
[root@mfs-client mfsdata]# mfscheckfile a
a:
[root@mfs-client mfsdata]# mfsfileinfo a
a:
2、回收
一个删除文件能够存放在一个“垃圾箱”的时间就是一个隔离时间,这个时间可以用 mfsgettrashtime 命令来验证,也可以用 mfssettrashtime 命令来设置。例如:
[root@mfs-client mfsdata]# mfsgettrashtime test.file
test.file: 86400
[root@mfs-client mfsdata]# mfssettrashtime 0 test.file
test.file: 0
$ mfsgettrashtime /mnt/mfs-test/test1
/mnt/mfs-test/test1: 0
这些工具也有个递归选项-r,可以对整个目录树操作,例如:
[root@mfs-client mfsdata]# mfsgettrashtime -r dir
dir:
files with trashtime 86400 : 3
directories with trashtime 86400 : 4
[root@mfs-client mfsdata]# mfssettrashtime -r 0 dir
dir:
inodes with trashtime changed: 7
inodes with trashtime not changed: 0
inodes with permission denied: 0
[root@mfs-client mfsdata]# mfsgettrashtime -r dir
dir:
files with trashtime 0 : 3
directories with trashtime 0 : 4
时间的单位是秒(有用的值有:1小时是3600秒,24 – 86400秒,1 – 604800秒)。就像文件被存储的份数一样, 为一个目录 设定存放时间是要被新创建的文件和目录所继承的。数字0意味着一个文件被删除后, 将立即被彻底删除,在想回收是不可能的
删除文件可以通过一个单独安装 MFSMETA 文件系统。特别是它包含目录 / trash (包含任然可以被还原的被删除文件的信息)和 / trash/undel (用于获取文件)。只有管理员有权限访问MFSMETA(用户的uid 0,通常是root)。
在开始mfsmount进程时,用一个-m或-o mfsmeta的选项,这样可以挂接一个辅助的文件系统MFSMETA,这么做的目的是对于意外的从MooseFS卷上删除文件或者是为了释放磁盘空间而移动的文件而又此文件又过去了垃圾文件存放期的恢复,例如:
mfsmount -m /mnt/mfsmeta
需要注意的是,如果要决定挂载mfsmeta,那么一定要在 mfsmaster 的 mfsexports.cfg 文件中加入如下条目:
* . rw
原文件中有此条目,只要将其前的#去掉就可以了。
否则,你再进行挂载mfsmeta的时候,会报如下错误:
mfsmaster register error: Permission denied
下面将演示此操作:
$ mfssettrashtime 3600 /mnt/mfs-test/test1
/mnt/mfs-test/test1: 3600
从“垃圾箱”中删除文件结果是释放之前被它站用的空间(删除有延迟,数据被异步删除)。在这种被从“垃圾箱”删除的情况下,该文件是不可能恢复了。
可以通过mfssetgoal工具来改变文件的拷贝数,也可以通过mfssettrashtime工具来改变存储在“垃圾箱”中的时间。
在 MFSMETA 的目录里,除了trash和trash/undel两个目录外,还有第三个目录reserved,该目录内有已经删除的文件,但却有一直打开着。在用户关闭了这些被打开的文件后,reserved目录中的文件将被删除,文件的数据也将被立即删除。在reserved目录中文件的命名方法同trash目录中的一样,但是不能有其他功能的操作。
3、快照
MooseFS系统的另一个特征是利用mfsmakesnapshot工具给文件或者是目录树做快照,例如:
$ mfsmakesnapshot source … destination
Mfsmakesnapshot 是在一次执行中整合了一个或是一组文件的拷贝,而且任何修改这些文件的源文件都不会影响到源文件的快照, 就是说任何对源文件的操作,例如写入源文件,将不会修改副本(或反之亦然)。
文件快照可以用mfsappendchunks,就像MooseFS1.5中的mfssnapshot一样,,作为选择,二者都可以用。例如:
$ mfsappendchunks destination-file source-file …
当有多个源文件时,它们的快照被加入到同一个目标文件中(每个chunk的最大量是chunk)。五、额外的属性文件或目录的额外的属性(noowner, noattrcache, noentrycache),可以被mfsgeteattr,mfsseteattr,mfsdeleattr工具检查,设置,删除,其行为类似mfsgetgoal/mfssetgoal or或者是mfsgettrashtime/mfssettrashtime,详细可见命令手册。
二、综合测试
1、破坏性测试
a、模拟MFS各角色宕机测试
b、mfs 灾难与恢复各种场景测试
2、性能测试
针对 MooseFS 的性能测试,我这边也没有详细去做。通过伟大的互联网,我找到了几位前辈,针对 MooseFS 所做的详细性能测试,这里我就贴出来展示一下。
1、基准测试情况:
随机读
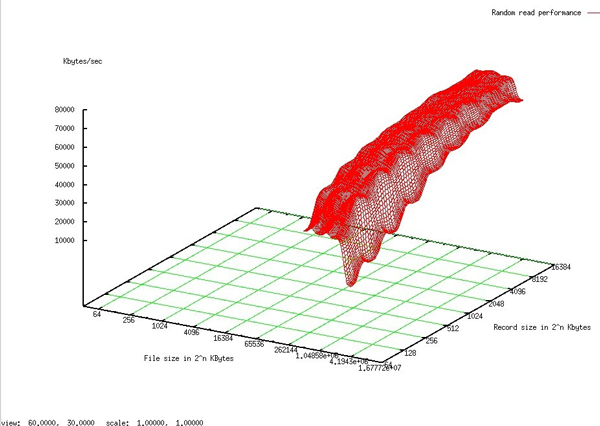
随机写
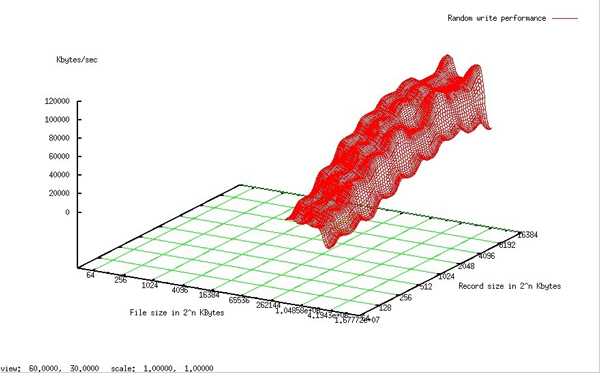
顺序读
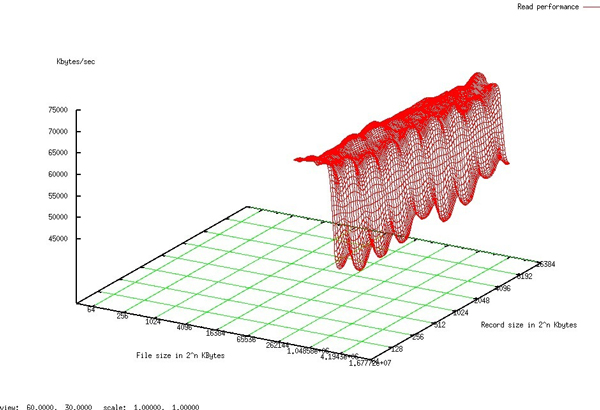
顺序写
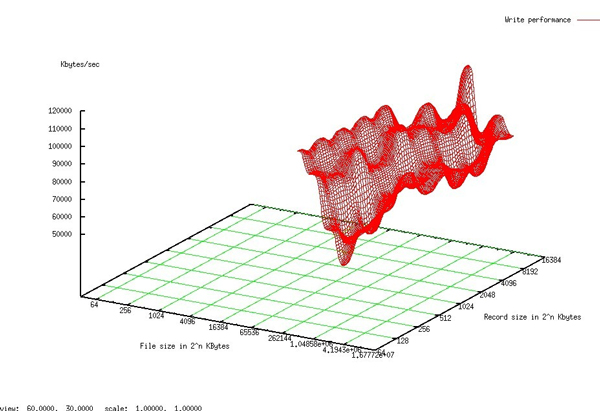
小文件性能测试情况:
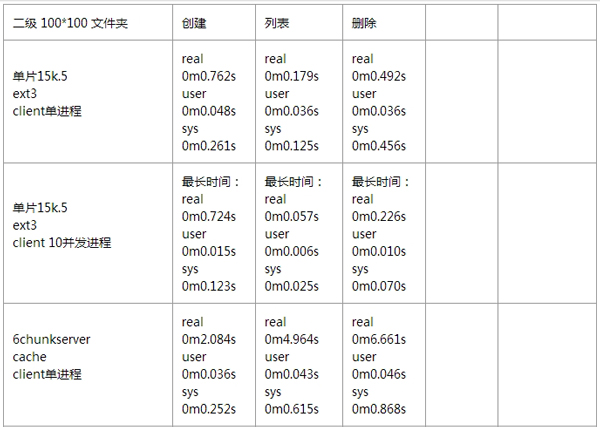
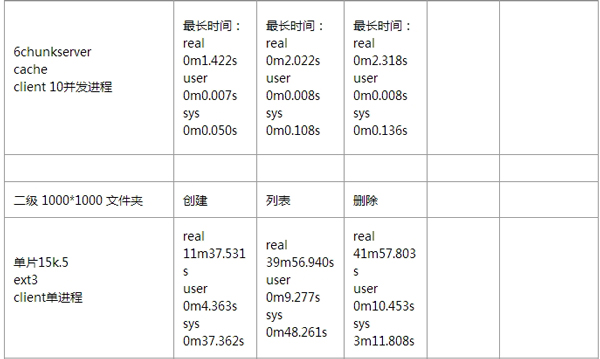
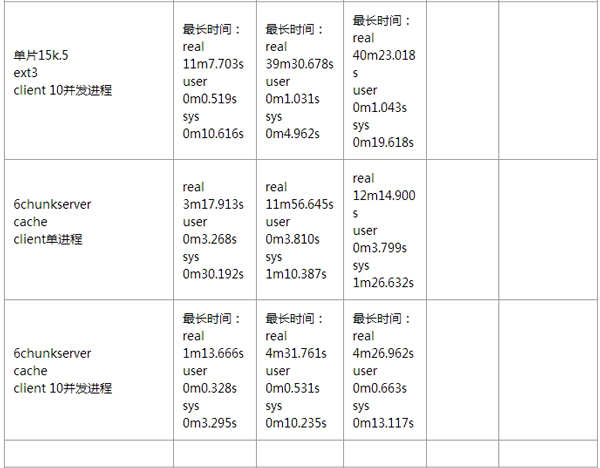
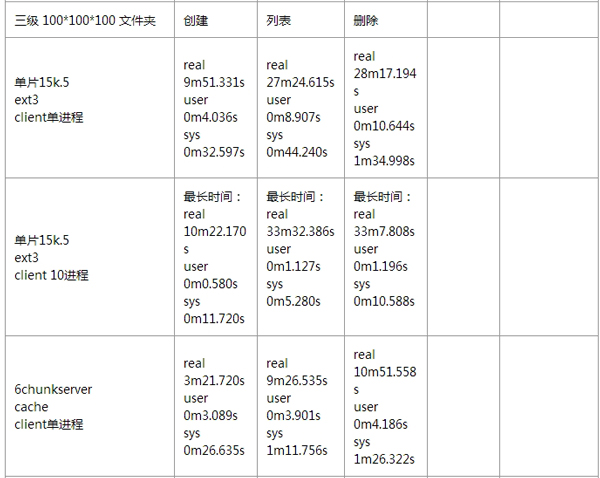
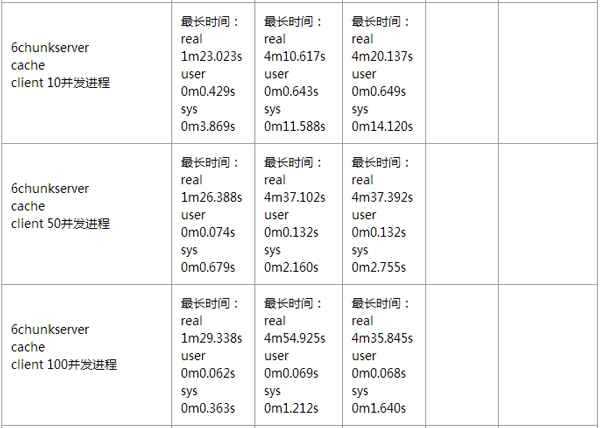
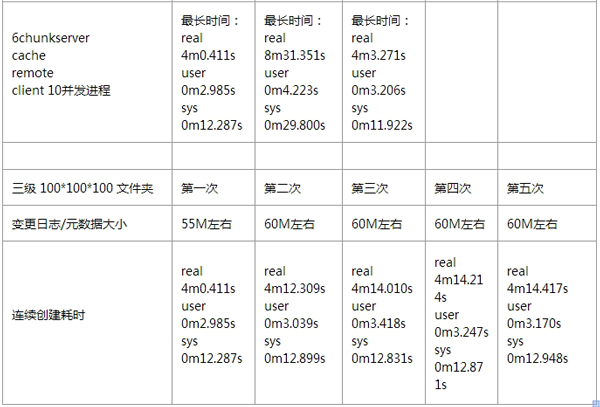
如果想看更多有关 MooseFS 性能方面的测试报告,可以去参考如下链接:
http://blog.liuts.com/post/203/ MooseFS性能图表[原创]
三、监控
1、mfs内置的监控工具mfscgiserv
针对 Moosefs 每个组件的监控,Moosefs自带了一个监控工具 mfscgiserv,它是一个 python 编写的 web 监控页面,监听端口为9425。该监控页面为我们提供了 Master Server、Metalogger Server、Chunk Servers以及所有Client挂载的状态信息及相关性能指标图示。
在我们安装好 Master Server 时,它就已经默认安装上了,我们可以在/usr/local/mfs/share/mfscgi/ 目录下看到这个监控页面的文件。
[root@mfs-master-1 mfs]# ll /usr/local/mfs/share/mfscgi/ # 这个 mfscgi 目录里面存放的是master图形监控界面的程序
total 136
-rwxr-xr-x. 1 root root 1881 Dec 29 00:10 chart.cgi
-rw-r–r–. 1 root root 270 Dec 29 00:10 err.gif
-rw-r–r–. 1 root root 562 Dec 29 00:10 favicon.ico
-rw-r–r–. 1 root root 510 Dec 29 00:10 index.html
-rw-r–r–. 1 root root 3555 Dec 29 00:10 logomini.png
-rwxr-xr-x. 1 root root 107456 Dec 29 00:10 mfs.cgi
-rw-r–r–. 1 root root 5845 Dec 29 00:10 mfs.css
我们可以通过执行如下命令启动该监控程序。
1
/moosefs_install_path/sbin/mfscgiserv start
启动完毕之后,我们可以通过访问http://IP:9425来访问该监控页面。
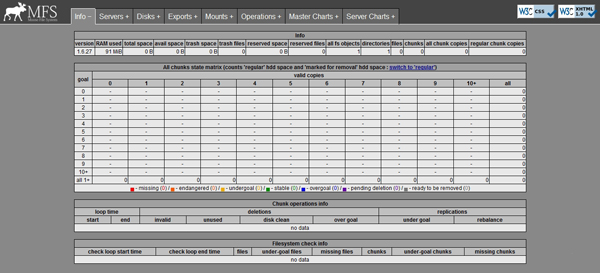
下面,我列出启动 mfscgiserv 监控工具的操作:
[root@mfs-master-1 mfs]# /usr/local/mfs/sbin/mfscgiserv start # 启动mfs图形控制台
lockfile created and locked
starting simple cgi server (host: any , port: 9425 , rootpath: /usr/local/mfs-1.6.27/share/mfscgi)
[root@mfs-master-1 mfs]# netstat -lantup|grep 9425
tcp 0 0 0.0.0.0:9425 0.0.0.0:* LISTEN 7940/python
tcp 0 0 172.16.100.1:9425 172.16.100.100:50693 ESTABLISHED 7940/python
tcp 0 0 172.16.100.1:9425 172.16.100.100:50692 ESTABLISHED 7940/python
[root@mfs-master-1 mfs]# lsof -i tcp:9425
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 7940 root 3u IPv4 27066 0t0 TCP *:9425 (LISTEN)
python 7940 root 7u IPv4 27136 0t0 TCP 172.16.100.1:9425->172.16.100.100:50693 (ESTABLISHED)
python 7940 root 8u IPv4 27124 0t0 TCP 172.16.100.1:9425->172.16.100.100:50692 (ESTABLISHED)
下面是访问的页面:
spacer.gifwKiom1Szsl2Cl8fyAAUfoEFIMdM006.jpg
2、使用zabbix监控mfs
1、监控要点
根据 MooseFS 中各个组件的特点,我们所需要监控的要点主要有如下几点:
a、Master Server的9420、9421端口,Chunk Server 的9422端口
b、Chunk Server 的磁盘空间
2、实施步骤
通过在各个组件的对应服务器上部署好zabbix监控的代理端,然后分别添加端口监控和磁盘监控即可!
操作过程略!
四、维护
1、常用管理命令
mfsgetgoal # 获取mfs目录、文件的副本数
mfssetgoal # 设置mfs目录、文件的副本数
mfscheckfile # 查看副本数简单
mfsfileinfo # 查看详细的副本数,chunks/分片
mfsdirinfo # 以数量的方法显示mfsfileinfo
mfsgettrashtime # 获取垃圾箱的定隔时间
mfssettrashtime # 设置垃圾箱的定隔时间(和memcached类)
mfsmakesnapshot # 快照
2、可能存在的问题
A、mfscgiserv的访问安全问题
mfscgiserv只是一个非常简单的HTTP服务器,只用来编写运行MooseFS CGI脚本。它不支持任何的附加功能,比如HTTP认证。如果公司出于对监控界面的安全访问需求,我们可以使用功能丰富的HTTP服务器,比如apache、nginx等。在使用这些更强大的HTTP服务器时,我们只需要将CGI和其它数据文件(index.html、mfs.cgi、chart.cgi、mfs.css、logomini.png、err.gif)存放到选择的站点根目录下。我们可以创建一个新的虚拟机,来设定特定的主机名和端口来进行访问。
B、Master Server 的单点问题
Master server的单点问题,在前面介绍 MooseFS 的优缺点时已经提到过了。由于官方提供的解决方案,在恢复的时候还是需要一定时间的,因此我们建议使用第三方的高可用方案(heartbeat+drbd+moosefs)来解决 Master Server 的单点问题。
3、性能瓶颈的解决办法
由于 MooseFS 的高可扩展性,因此我们可以很轻松的通过增加 Chunk Server 的磁盘容量或增加 Chunk Server 的数量来动态扩展整个文件系统的存储量和吞吐量,这些操作丝毫不会影响到在线业务。
4、安全开启/停止MFS集群
1、启动 MooseFS 集群
安全的启动 MooseFS 集群(避免任何读或写的错误数据或类似的问题)的步骤如下:
1、启动 mfsmaster 进程
2、启动所有的 mfschunkserver 进程
3、启动 mfsmetalogger 进程(如果配置了mfsmetalogger)
4、当所有的 chunkservers 连接到 MooseFS master 后,任何数目的客户端可以利用 mfsmount 去挂载被 export 的文件系统。(可以通过检查 master 的日志或是 CGI 监控页面来查看是否所有的chunkserver 被连接)。
2、停止 MooseFS 集群
安全的停止 MooseFS 集群的步骤如下:
1、在所有的客户端卸载MooseFS 文件系统(用umount命令或者是其它等效的命令)
2、用 mfschunkserver –s命令停止chunkserver进程
3、用 mfsmetalogger –s命令停止metalogger进程
4、用 mfsmaster –s命令停止master进程
5、增加块设备(会自动平均)
针对增加块设备的情况,其实就是说针对chunk server 有变化(增加或减少)的情况。
为了增加一个案例说明,这里就以 UC 在使用 MooseFS 中遇到的一个问题为案例,讲解新增加 chunk server 时,MooseFS集群发生的变化,其实也就是 Master Server 发生的变化。
UC在使用 MooseFS 集群的过程中,有次一台 Chunk Server 挂了,于是就涉及到了后期的恢复问题。在问题Chunk Server修复之后,就从新加入到了集群当中。此时,新增加的 chunk server 启动之后会向 Master 汇报 Chunk 的信息,Master接收到 Chunk 信息之后会逐个检查 Chunk_id是否存在。如果不存在,就表示该chunk_id其实已经删除了(chunk_id过期),然后会调用chunk_new()创建该chunk,并设置lockedio属性为7天后。这些操作都是属于内存操作,并且Master是单线程的进程,并不存在全局锁,因此不会导致 Master 阻塞无响应。因此,针对增加chunk server的情况,是不会对MooseFS集群产生什么大的影响的。
以上就是新增加 Chunk Server 后的,MooseFS 集群中 Master Server 的变化。而针对各个Chunk Server,Master Server会重新去调整块文件的磁盘空间,然后全部重新动态分配块文件。如果遇到空间不够的磁盘,Master Server会自动调整块文件的分布,从不够的磁盘里动态的把块服务移动到有大的磁盘块服务器里
当然,如果按照上面的情况这次就不会是故障了,因此并不会对 MooseFS 集群产生什么大的影响。由于他们当时因为资源紧张,就把 Master Server 放到了虚拟机上,而虚拟机的磁盘是挂载的iscsi磁盘。并且他们的MooseFS使用的版本并不是最新的1.6.27,而是1.6.19。在1.6.19版本中,会把chunk的汇报过程写入磁盘,这样就导致了几十万条的磁盘写入,由于磁盘是前面提到的网络盘,就最终酿成了 Master Server 恢复时无响应几十分钟。
因此,我们在生产环境中,针对Master Server的选型一定不能使用虚拟机,而是使用大内存量的物理机。