

OpenAI、Google等使用的大模型数据集泄露约12000个API密钥和密码
责编:gltian |2025-03-04 16:40:09近日,研究人员在用于训练人工智能模型的Common Crawl数据集中发现了11908个API密钥、口令以及密码等敏感信息。

作为全球最大的开源网络数据集之一,Common Crawl自2008年起持续收集PB级Web数据,并免费向公众开放。鉴于数据集的庞大体量,许多人工智能项目可能至少在一定程度上依赖这些数字档案来训练大型语言模型(LLM),其中包括OpenAI、DeepSeek、Google、Meta、Anthropic和Stability等公司的模型。
尽管Common Crawl的开放共享在很大程度上促进了全球人工智能技术的迅猛发展,但同时也有可能会带来严重的安全风险。
网络安全公司Truffle Security在对Common Crawl 2024年12月存档的26.7亿个网页的400TB数据进行扫描时,发现了11908个经过成功验证的密钥。这些密钥被开发人员硬编码,表明LLM有可能在不安全的代码基础上接受了训练。
值得注意的是,LLM的训练数据不能直接以原始形式使用,必须经过预处理阶段,包括清理和过滤掉不相关的数据、重复项,以及有害或敏感信息等不需要的内容。
研究人员在分析扫描数据后,发现大量Amazon Web Services (AWS)、MailChimp和WalkScore服务的有效API密钥。

研究人员在Common Crawl数据集中识别出219种不同的密钥类型,最常见的是MailChimp API密钥。约1500个Mailchimp API密钥在前端HTML和 JavaScript中进行了硬编码。
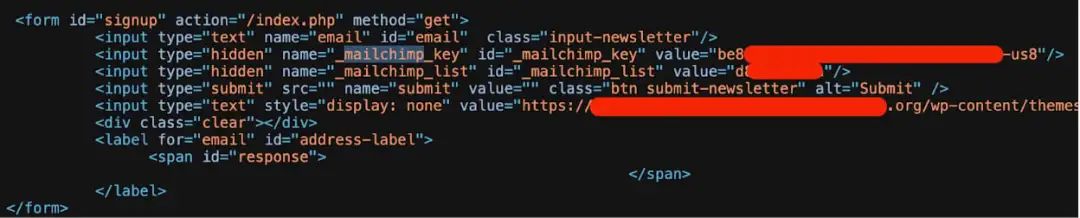
研究人员指出,威胁攻击者可能会利用上述密钥继续进行恶意活动,例如网络钓鱼活动和品牌冒充。不仅如此,密钥也可能会导致数据泄露。泄露的潜在影响包括:
- 恶意活动:威胁攻击者可以利用泄露的API密钥发起钓鱼攻击、品牌冒充或其他恶意活动。
- 数据外泄:密钥泄露将引发敏感数据如用户信息、财务数据及医疗记录被非法获取的风险。
- 服务滥用:攻击者滥用密钥可非法访问保护服务,进而给服务提供商带来经济损失和声誉风险。
- 高重复使用率:63%泄露密钥跨页面重复使用,加剧安全风险,一旦泄露,将波及多个服务和页面。
Truffle Security在发现这一安全风险后,迅速联系了受影响的供应商,并协助他们撤销和更换密钥。目前来看,尽管LLM训练数据在预处理阶段会进行清理和过滤,但完全去除敏感信息仍然具有挑战性。
文章来源 | bleeping computer
声明:本文来自赛博研究院,稿件和图片版权均归原作者所有。所涉观点不代表东方安全立场,转载目的在于传递更多信息。如有侵权,请联系rhliu@skdlabs.com,我们将及时按原作者或权利人的意愿予以更正。
- OpenAI、Google等使用的大模型数据集泄露约12000个API密钥和密码
- 因违反网络安全合规要求,这家公司被罚超1000万元
- Gartner:随着GenAI技术全球采用,数据跨境流动风险增加
- 360发布DeepSeek大模型一体机!开箱即用,打通大模型落地最后一公里
- 网络安全实战人才培养的难点和对策
- 国内网络安全上市公司2024年业绩快报统计
- 肚脑虫 (APT-Q-38) 利用PDF文档诱饵的攻击活动分析
- NAKIVO Backup & Replication任意文件读取漏洞安全风险通告
- 朝鲜黑客窃取了价值超百亿元的加密货币,单次金额创历史新高
- 实时威胁检测薄弱!《2025年全球云安全报告》深度解读