

网络钓鱼技术之HTML走私
责编:gltian |2021-06-22 10:58:27
前言
今天介绍一种走私技术,HTML Smuggling,这不是一种特别新的攻击方法,但是它确实在越来越多的攻击场景中出现,其中就包括网络钓鱼。接下来我们就来了解一下HTML走私的来龙去脉以及它在钓鱼中是怎样被利用的吧。
HTML走私介绍
什么是HTML走私?HTML走私是指,浏览器根据HTML文件的内容在主机上创建恶意文件,而不是直接转发/下载恶意软件的一种技术。HTML走私可以通过在HTML页面中将恶意文件隐藏为编码后的“string”来绕过外围安全性检查和在线检测。
大多数周边/在线安全检测方法都是通过匹配文件中的某些特定模式。但在HTML走私的情况下,恶意文件被嵌在浏览器中,所以检测这样隐藏的代码是困难的。而且由于代码中的混淆,甚至检测HTML走私这种情况本身也很困难。
利用方法
在去年也就是2020年的网络钓鱼调查中,我遇到了两种本质上不同的HTML走私方式。这两种方案都将数据存储在HTML文件中,并且提供了无需向服务器发送额外请求就可以“下载”数据的方法。此外,这两种方案都是基于HTML5的下载属性(虽然不是强制性的但是有好处)。
Javascript Blob
先介绍第一种方案,基于JavaScript Blob,也是我经常看到的方案。Blob对象表示一个不可变、原始数据的类文件对象。它的数据可以按照文本或二进制的格式进行读取,也可以转换为ReadableStream来读取。借助Blob,我们可以将我们的恶意文件存储在HTML代码中,然后将其置入浏览器中,而不是直接向Web服务器发送文件上传请求。
我们可以通过下面两个链接来创建我们的HTML页面:
https://gist.github.com/darmie/e39373ee0a0f62715f3d2381bc1f0974
要存储文件,首先,需要将文件编码为base64,可以在PowerShell中使用一下代码来实现:
$base64string = [Convert]::ToBase64String([IO.File]::ReadAllBytes($FileName))
然后替换下面html文件中<>所指的值。fileName变量表示你希望在默认情况下下载文件的名称。base64_encoded_file变量存储base64编码后的文件。
<html>
<body>
<script>
var fileName = <>
var base64_encoded_file = <>
function _base64ToArrayBuffer(base64,mimeType) {
var binary_string = window.atob(base64);
var len = binary_string.length;
var bytes = new Uint8Array( len );
for (var i = 0; i < len; i++) {
bytes[i] = binary_string.charCodeAt(i);
}
return URL.createObjectURL(new Blob([bytes], {type: mimeType}))
}
var url = _base64ToArrayBuffer(base64_encoded_file,'octet/stream')
const link = document.createElement('a');
document.body.appendChild(link);
link.href = url;
link.download = fileName;
link.innerText = 'Download';
</script>
</body>
</html>
现在只要我们点击上面的链接,就会开始下载步骤。
DataURL
实现HTML走私的另一种方案是使用DataURL。这种解决方案就不需要使用JavaScript了。使用DataURL进行HTML走私的目标就是将较小的文件嵌入HTML文件中。
虽然上面强调了小文件,但是实际上,限制也不是很严格。DataURL的最大长度由浏览器中的最大URL长度决定。比如,在Opera中,这个大小是65535个字符,虽然这个字节数对于转移1080p的电影来说是远远不够的,但是用来反弹shell已经足够了。
这种方法比第一种基于JS Blob的要简单得多。先看一下语法:
data::前缀;
[<mediatype>]:可选项,是一个MIME类型的字符串,比如我们最常见的image/jpeg表示JPEG图像,如果缺省,默认值为text/plain;charset=US-ASCII;
[;base64]:可选项,如果数据是base64编码的,那么就用;base64标记
,:将数据与控制信息分开;
<data>:数据本身。
<html>
<body>
<a href="data:text/x-powershell;base64,aXBjb25maWcNCmhvc3RuYW1l"
download="test.ps1">
Download
</a>
</body>
</html>
这是一个简单的HTML例子,加载该页面的时候会显示一个download按钮。我们点击下载,浏览器就会将test.ps1文件保存到我们的电脑上。而写入的内容自然就是aXBjb25maWcNCmhvc3RuYW1l base64解码后的内容。
发现了一个比较有意思的事情。当讲将<a>标签中的download去掉后,也就是变成了下面的样子:
<html>
<body>
<a href="data:text/x-powershell;base64,aXBjb25maWcNCmhvc3RuYW1l" >
Download
</a>
</body>
</html>
我们重新在Chrome浏览器中打开并尝试下载,这个时候发现,这个按钮已经失效了,点击不会有任何反应。但是用Firefox打开,依旧可以下载文件,只不过firefox会创建一个随机的文件名,并且保存的文件不会有后缀:
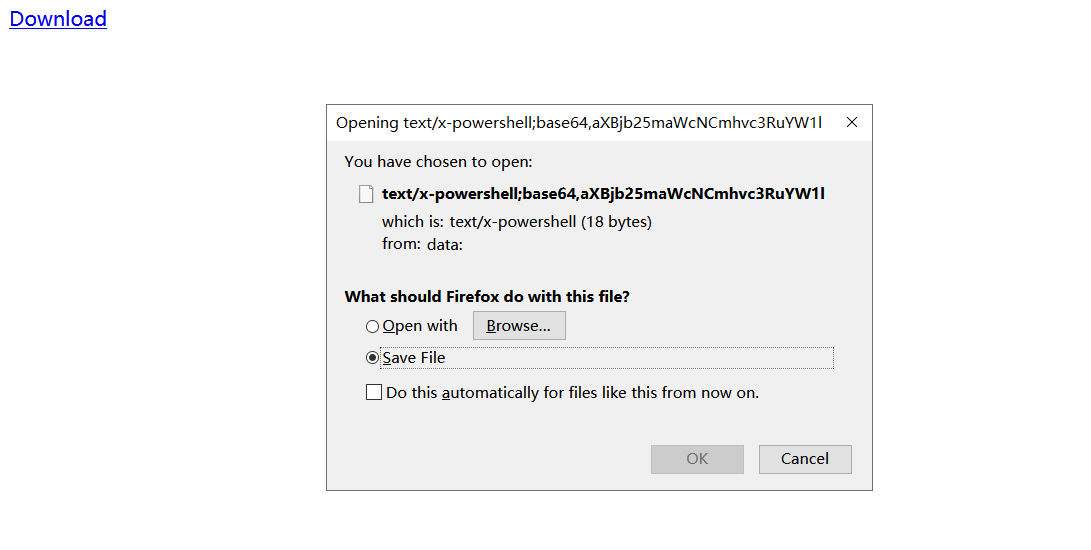
综上,我们可以将DataURL和JS Blob相结合来添加一个函数,当然我们可以不适用任何脚本,但是和上面的例子中的问题一样,显然会更到更多的限制。
为什么攻击者会使用HTML走私?
HTML走私是钓鱼攻击一个很好的补充。在HTML走私的帮助下,攻击者可以逃避一些检测和记录机制。在这种方式下,文件被“注入”到HTML文档中,而绝大多数的安全解决方案根本不会去检测。
当然HTML走私也有一些缺点。首先,它需要用户交互,虽然浏览器会自动处理恶意文件,但是下载到用户主机还是需要用户同意,除非配置了未经用户确认的自动下载。而且即使文件被下载了,还是需要将其执行。
利用HTML走私来钓鱼
上面介绍了两种常见的HTML走私方法,回到文章的主题,如何利用HTML走私来进行钓鱼呢?这里介绍两种比较常见的方法。首先,第一种是让电子邮件包含一个指向外部网页的链接,而该指向的网页使用了HTML走私技术。这是比较常见的邮件钓鱼方式。另一种方法是,在电子邮件中添加一个HTML附件,该HTML文件走私了恶意代码,这种情况下,用户打开的就是本地的HTML文件,不需要访问外部站点。
在这两种情况下,好处是恶意内容很难被检测到,因为恶意代码隐藏在HTML内容中。通过这种方式,可以绕过很多道安全防御。
正常文件下载
首先,我们来看一下正常的文件下载步骤是怎样的。在下图的例子中,用户访问一个网站,然后下载一个exe文件:
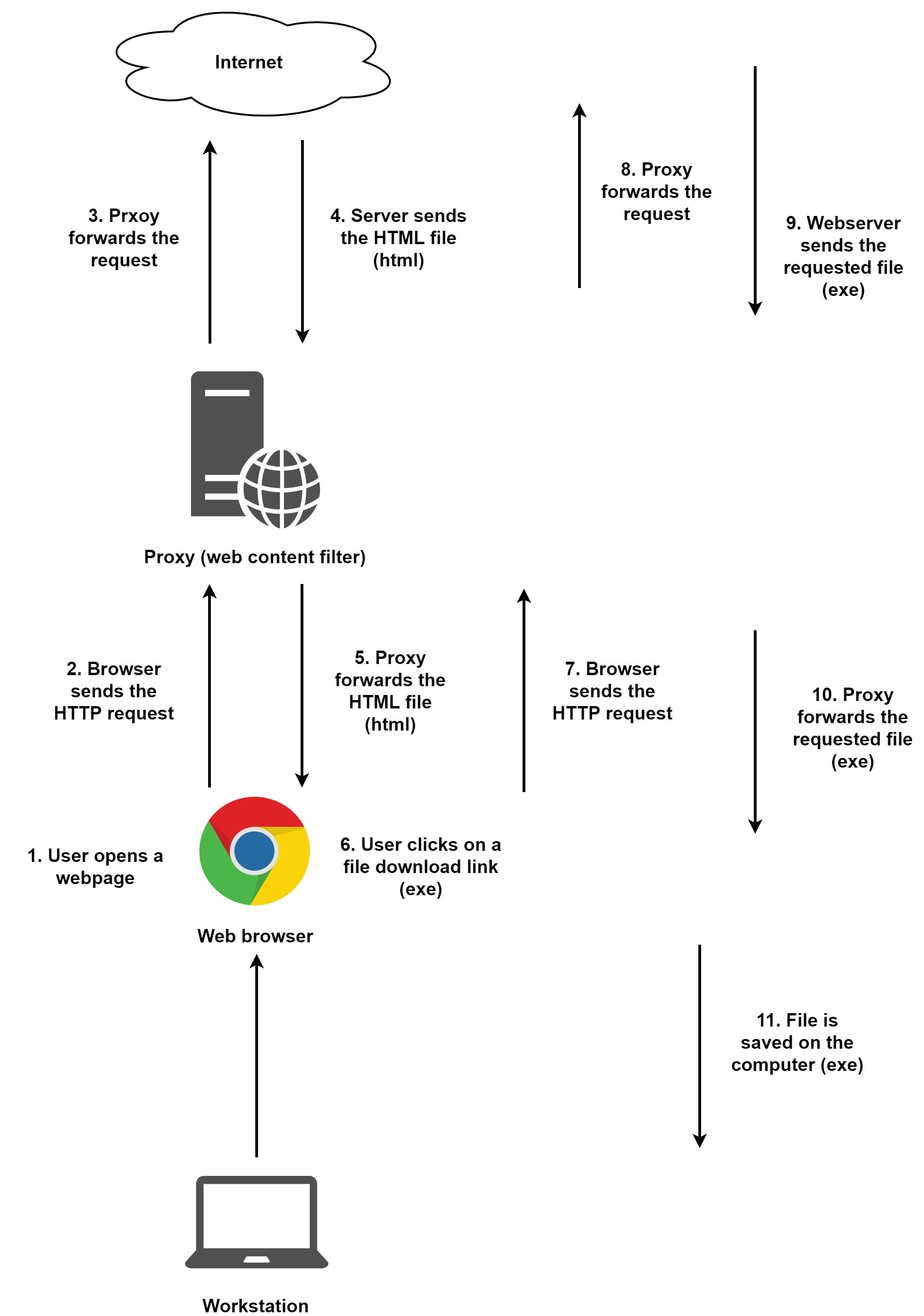
1 . 首先,用户打开一个正常的网站。这个网站可以是用户自己输入的,也可以从包含链接的钓鱼邮件中获得。
2 . 浏览器向网站发送HTTP请求。如果存在代理,那么这个流量就会走代理。
3 . 代理会检查浏览器请求的URL。因为许多的代理都有检查域信誉的能力,如果代理认为请求的域是恶意的,那么Proxy不会进行后续的请求,通信将在这一步就停止;反之,代理会将请求转发给Web服务器。
4 . Web服务器返回请求的资源给代理,在本例中,Web服务器返回的就是一个普通的HTML页面。
5 . 代理检查Web服务器的响应。在这一步会进行各种过滤。代理可以阻止用户下载一些类型的文件。此外,代理可以有一个内置的沙箱来测试文件是否安全,而HTML文件通常不会再沙箱中进行测试就被允许通过代理转发给用户。
6 . 页面通过代理转发给浏览器。此时判断文件可信度的角色就变成了用户,用户可以决定浏览器中显示的某个文件是否安全,如果用户信任,就可以进行文件下载,在本例中,该文件是一个exe文件。
7 . 浏览器向Web服务器发送文件下载请求。
8 . 代理的处理和之前相同,这一步没什么区别。
9 . Web服务器将请求的exe文件发送给代理。
10 . 当代理获得该exe文件时候,它会对其进行综合性评估。如果设置了网络中禁止下载exe文件,那么显然,exe下载请求在这一步就结束了,文件将无法到达用户的机器。代理还会检查文件是否是已知的恶意文件。此外,它还可以决定是不是要将文件放到沙箱中进行测试。这里有一个关键点,当代理知道这个文件是一个可执行文件时候,它可以决定是不是要继续转发。而且,网络分路器(Network Taps)可以检测到这个exe文件,如果它们认为该文件是恶意的,也可以阻止用户下载该文件。
11 . 如果一切顺利,那么文件就到达了它的最终目的地——用户的电脑。
在上面的步骤中,最重要的一步就是第10步。这一步有普通文件下载和HTML走私下载的最大区别。在正常下载的情况下,exe文件易于检测和评估(比如检查散列,沙箱执行检查,收集头文件信息来判断等等)。而在HTML走私的情况下,文件不会以一种未编码的方式在网络上传播,它总是会被嵌入到另一个HTML文件中。
通过e-mail中的外部链接
首先,先介绍一种很常见的走私技巧。在这种情况下,攻击者会将事先准备好的链接放入电子邮件中。该链接会指向包含走私文件的外部链接。在这种情况下,恶意的内容不会通过电子邮件的网关,而是以隐藏的形式,通过代理被用户访问。
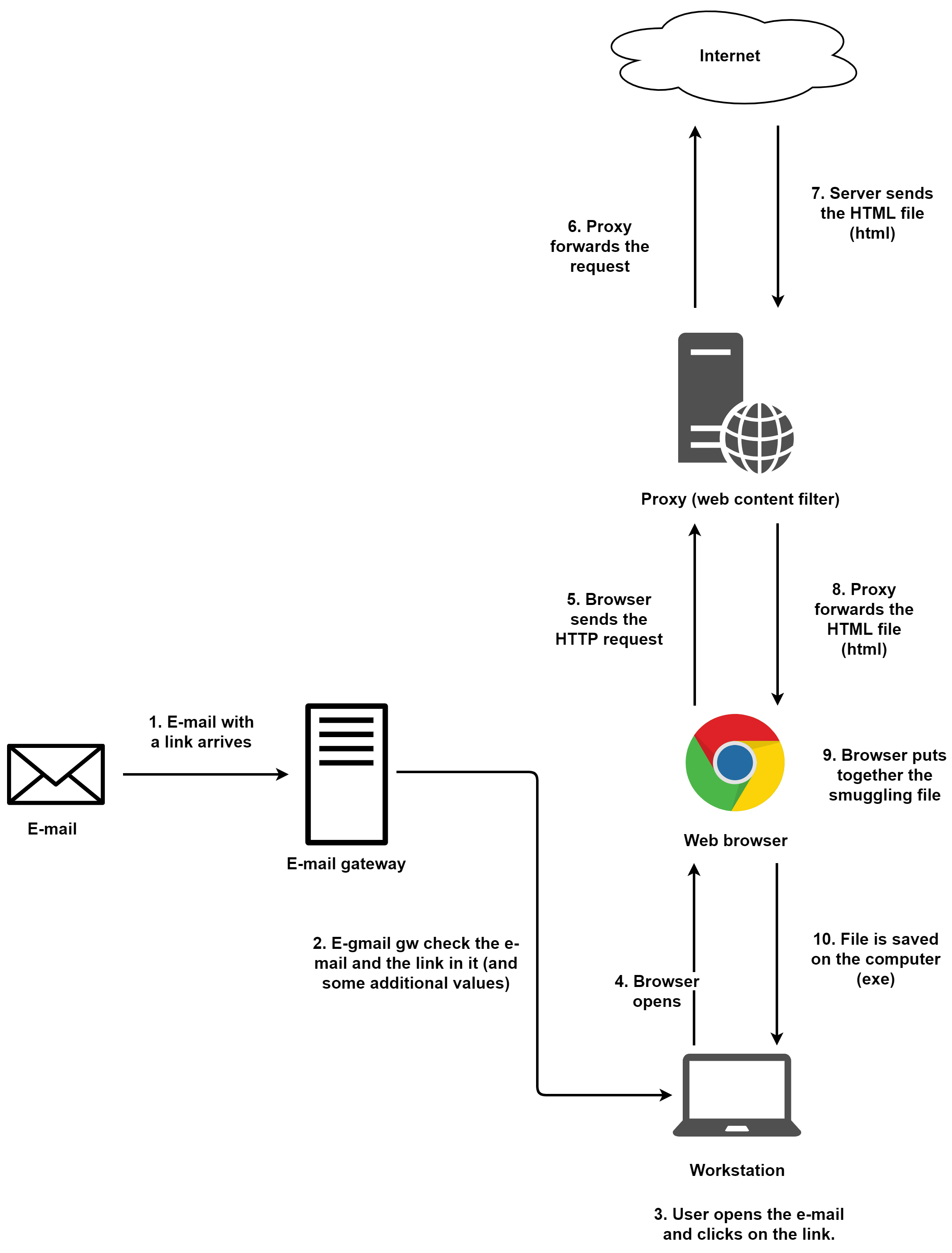
1 . 有一个带着外部链接的e-mail向目标用户发送。
2 . 邮件网关对邮件进行检查。在这一步有很多种检查方法,但在本例的场景下,我们就认为邮件网关并不会阻拦该邮件,因为这里没有包含什么恶意文件。
3 . 用户点击邮件中的链接。
4 . 默认浏览器启动。
5 . 浏览器向存储(或是生成)HTML文档的外部站点发送HTTP请求。
6 . 代理会进行一些必要的检查,但是如果该URL并没有被加入黑名单,那么该请求就会被转发到该站点所对应的服务器。
7 . 服务器返回HTML页面以及隐藏在其中的exe文件。exe文件是以字符串的形式存储在文档中,此时它已经变成了HTML内容的一部分。
8 . 代理会检查响应内容。在本例中,响应只是一个HTML文件,代理不会去拦截HTML文件。而且,HTML文件在绝大多数情况下不会被转发到沙箱中执行检查。因而,隐藏在HTML文档中的恶意内容几乎不会在这里被检测到。当然通过其他的检测技术,它们也可能能识别到HTML走私技术(但是这里指的也只是HTML走私这件事本身,而不是隐藏在HTML中的恶意文件)。现在我们就认为代理没有识别出这个情况,将响应HTML页面转发给浏览器。
9 . 浏览器重新拼接嵌入在HTML页面中的字符串,然后启动下载进程。
10 . 最后恶意exe文件被存储到用户的电脑上。
我们可以看到,在这种情况下,e-mail的安全检查机制并不能起到太大的作用。因为电子邮件本身不是恶意的,其中的链接可以是合法的链接。
代理当然可以查看HTML文件,但是很少有安全性检测方案会对HTML文件进行彻底地处理。大多数情况下,这些文件都是被允许通过代理的。IDS解决方案还倾向于依赖检测文件扩展名或是magic bytes(主要是通过分析文件的第一个字节来判断文件的类型),因此文件中的编码字符串很难被它们捕获。但是其实我们可以创建一个模式匹配解决方案来检测一些隐藏在HTML中的东西。这在后面会提到。
通过电子邮件中的HTML附件
这种方法是指包含走私的HTML文件被附加到了电子邮件中。
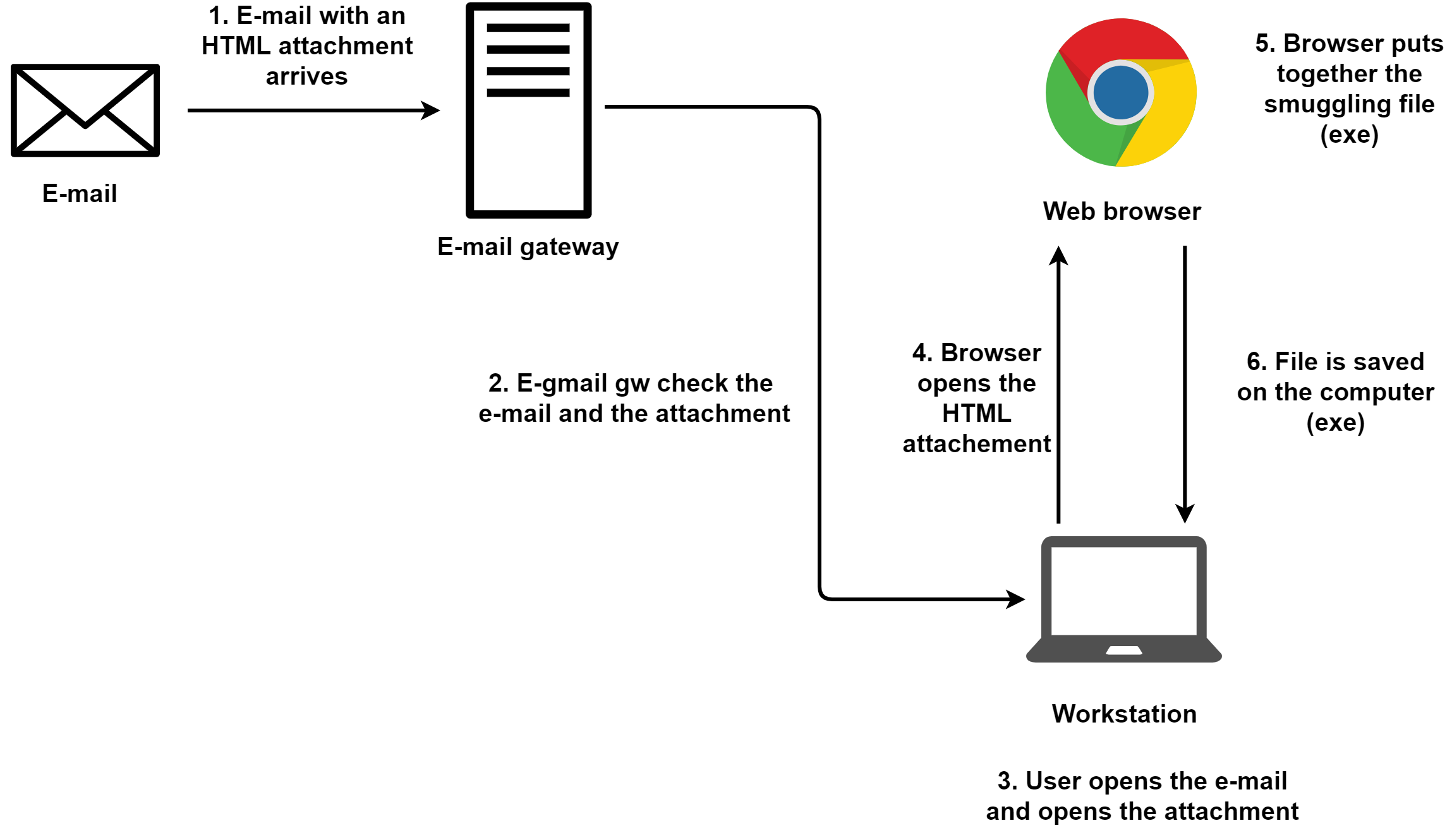
1 . 邮件网关收到一份带有HTML附件的电子邮件。
2 . 邮件网关会对电子邮件中附带的HTML进行检查。如果检查未通过,那么邮件网关会阻击电子邮件的后续转发或者选择删除附件。但是,现在还没有听说过什么电子邮件安全解决方案能够通过静态分析或者动态分析来检测HTML走私(即使是在HTML走私的是恶意代码。)
3 . 用户打开HTML附件。
4 . 浏览器打开并加载HTML文档。
5 . 浏览器处理HTML文件的内容,处理被走私的文件并将其提供给用户下载。
6 . 文件被保存到计算机上。当然,在这一步,要么需要用户的批准,要么需要浏览器设置了自动下载,就是未经确认的下载。
这种方法相比上一种的好处就在于,它不需要通过任何代理。而且,网络上的IDS/IPS安全检查通常不会去检查电子邮件,所以,如果攻击者能够成功欺骗电子邮件网关,那么在网络上就没有其他的难处了。
防御与检测
在这一小节中我们来探讨一下如何防御与检测HTML走私。
在发生了HTML走私的情况下,我们可以有两种检测方式,我们要么就关注HTML走私技术本身,要么可以尝试捕获隐藏在HTML文档中的恶意代码。
防御方法
这里介绍几种防御方法。
1. 禁止JavaScript执行
虽然对于HTML走私没有什么万能的防御办法。禁用JavaScript看起来是一种可行的方案,毕竟一种HTML走私技术就是基于JavaScript Blob的,但是,在企业环境中禁用JS肯定会带来很多问题。当然,如果在你遇到的显示场景中,禁用JS是可行的,那么也可以尝试这种方法,那么在这个时候,你只需要用模式匹配去识别DataURL是不是存在HTML走私情况就好。
2. 禁止邮件中的HTML附件
HTML走私的一种类型是使用HTML文件作为附件。不幸的是,这在很多场景中都是常见的,实际上,现在有很多带有HTML附件的合法的、与业务相关的电子邮件在增加。另一方面,不法分子也利用HTML附件来进行钓鱼。
如果你能在不影响业务的情况下阻止带有HTML附件的邮件,那么对于利用邮件中带有的HTML来进行钓鱼的路就被堵住了。那此时我们只需要关注邮件中附带的链接了。
我们可以看到,前面这两种防御方法都无法同时覆盖所有的HTML走私情况。在最好的情况下,我们可以使用这两种方案来防住部分HTML走私;在最坏的情况下,我们甚至都不能使用这些防御解决方案,因为这些方案在大多数现在企业环境中是不适用的。
3. Windows应用程序防护(Microsoft Defender Application Guard)
Microsoft Defender Application Guard是Windows提供的一种安全解决方案,主要用于隔离各种试图使用来自不可信源资源的应用程序,后面简称MDAG。MDAG有两种不同的形式。第一种是Application Guard for Edge,它主要是用来隔离企业定义的不受信任(或不特别受信任)的站点,在企业的员工浏览Internet时保护公司。Application Guard通过在一个启用了Hyper-V的隔离容器中打开站点来实现这一点。而且,它还与Firefox和Chrome浏览器兼容。
另一个版本是Application Guard for Office。它能够保护可信资源不受不可信资源的攻击。它也是通过在一个容器中打开不受信任的Word、Excel、PowerPoint文档来实现。当然,这也和HTML走私无关,所以就不继续讨论了。
Application Guard for Edge
我们已经知道,Application Guard for Edge主要是通过在隔离的虚拟环境中打开不受信任的链接来保护我们的系统。如此一来,一个未知的URL,或者说是一个恶意的URL就不会对主机造成危害了。下载的恶意文件会被隔离存储在隔离的环境中,而不会直接与宿主机接触。
如果一个链接在电子邮件中到达,并且给定的URL并不在Application Guard的白名单中,那么它就会在一个隔离的Edge中被打开。因为对于该URL的访问是在隔离的环境中进行的,那么每个文件下载行为也都是在这个隔离的环境中进行的,因此被走私的恶意文件不会对主机造成真实伤害。
当然,这个解决方案也并不是十全十美的。它也有一些缺点:
1 . 为了使Edge能发挥作用,你需要使用白名单和untrust来标记一切网站。这在大公司中,意味着相关的管理员需要承受巨大的负载。因为用户会不断地进行异常请求。
2 . 虽然Application Guard能够防住以链接形式附在电子邮件中的HTML走私请求,但是它无法防御以电子邮件附件形式传递的HTML走私。这些附件到达用户主机后,会作为本地文件在浏览器中打开,因此,这些文件不会被当作不受信任的域来处理,不会在隔离的Edge容器中打开这些HTML文件,也就不会触发Application Guard。因此通过电子邮件附件进行的HTML走私在这种情况下依然可以成功。
3 . 会影响用户访问站点的速度,因为需要启动容器。
检测方法
1. 模式匹配
如果HTML文件中没有利用JS来走私,而是仅仅使用了DataURL,在这种情况下,我们可以使用模式匹配(比如匹配data:)来判断是不是发生了HTML走私。我们可以实用IDS或是简单的YARA工具来检测,比如github上的开源工具LaikaBOSS就是一款可用的检测工具。
KaikaBOSS对于下载的文件(HTML文件),甚至是电子邮件附带的文件,都非常有效。它可以检测大量的数据,伸缩性很好,所以即使在大型环境中,也同样可以派上用场。
如果使用了JavaScript,那么可能代码是被混淆过的,此时模式匹配可能就不太有效果了。我们只能用其他的方法来检测混淆的代码。
2. 检测浏览器是否通过网络下载文件
在使用了HTML走私的场景下,被下载的文件是在浏览器中创建的,而在一般的下载场景中,我们可以看到,是需要我们向Web服务器发起请求,然后Web服务器传送给我们的,而且还会经过代理,经由代理检查文件的安全性。因此我们还可以通过关注普通文件下载和基于HTML文件创建下载文件之间的区别来鉴别HTML走私。因此我们可以通过查看代理日志、观察是否有浏览器进行在主机上创建文件等方式来查看是不是发生了HTML走私。
这种方式的缺点在于:
1 . 许多流量在默认情况下不会通过代理。比如,一些公司会配置它们的网络,使其内部网站无法通过代理访问。这个时候,如果通过浏览器生成了一个文件,但是没有代理日志。这种情况经常发生,不应该基于这种情况创建警报。
2 . 在一些情况下,用户可以绕过代理,也不会产生代理日志。
3 . 可以在浏览器中打开本地文件,然后保存为新文件,这也是浏览器创建的文件,同样没有代理日志。
如果用户是在上面的情况下进行合法行为,我们都不应该进行拦截,因此难点就在于我们很难区分这是不是一种走私情况。
3. 沙箱执行
您可以将HTML文件发送到沙箱,然后使用沙箱中的浏览器打开它。不是通过互联网访问的HTML文件除了一些临时文件之外,不应该在机器上创建任何文件。理论上,如果在没有网络访问的情况下,HTML文件在沙箱中创建了文件,那么沙箱应该要发出一个警报来提醒用户。
但是,经验表明,HTML文件通常不会放到沙箱中打开。它们可以通过静态分析进行检查(如LaikaBoss),也可以动态分析进行检查,但是动态分析将花费更多的时间,并且会显著降低网络速度。
但是沙箱这个解决方案在大多数的情况下不是特别友好,因为在转发给用户之前打开每个HTML文件负载也挺大的。而且,如果恶意文件是需要用户点击下载的,那么这种方式也行不通,只有在页面配置了自动下载的情况下,我们才能通过沙箱来检测。所以总体来说,这也不是一个特别好的方法。
4. 使用Zone.Identifier
另一种方式是使用取证分析中可能会使用的技术——Zone.Identifier来区分是不是发生了HTML走私。
由HTML走私创建的文件的Zone.Identifier是这样的(在新版Edge、Chrome和Firefox测试过):
[ZoneTransfer]
ZoneId=3
HostUrl=about:internet
而正常下载的文件的Zone.Identifier则是(这在不同的浏览器之间存在区别):
[ZoneTransfer]
ZoneId=3
ReferrerUrl=https://www.sans.org/security-resources/posters/windows-forensic-analysis/170/download
HostUrl=https://www.sans.org/security-resources/posters/windows-forensic-analysis/170/download
这种方法的局限就在于,它只能在Windows(NTFS)上这样做。因此这种方式也不是完全可靠的。
5. Chrome组件
Chrome会存储下载文件的来源,如果源是JavaScript Blob或是DataURL,那么这些信息就会作为源显示。
当我们打开一个本地的HTML被走私文件:

当然上面的信息不会告诉我们该被走私的恶意文件是从哪里下载的。
当我们访问远程的走私HTML文件时,我们就可以看到相应的恶意文件下载URL了,但是也仅仅是在走私文件是使用了JS Blob时能看到,在使用DataURL时则不会显示远程链接:

这种情况相比前面的几种方法看起来更加实用。在远程访问,并使用了JS Blob的情况下,我们甚至能看到恶意文件的真实来源,如果攻击者使用了DataURL,我们还可以利用这个信息重新生成文件,这在一些场景下可能也是有用的。
总结
总体来说,目前想要完全检测和防御HTML走私是一件比较困难的事情。当然,上面介绍的方法也只是相对简单地介绍了HTML走私下的钓鱼事情,在现实攻击场景中,可能会遇到更复杂的情况。
来源:安全客