

Snort数据包预处理模块源码分析
责编:gltian |2020-10-27 10:59:38一、前言
Snort是一款基于C语言开发的,开源轻量级网络入侵检测系统,虽然轻量但是功能强大,最近因为学校项目的缘故,对snort的源码进行了一些粗浅的分析,略有收获,作为笔记记录下来,同时也希望本文对大家有所帮助。
这是snort的官方网站:https://www.snort.org/
snort的基本使用方法和基础知识,网上资料丰富,这里就不再赘述了。
所以我们直入主题,也就是snort数据包预处理模块的源码分析,注意本文所分析的源码是snort2.2版本的,最新的2.9版本里面的函数模块和某些数据结构有所变动,但是基本上的功能还是一致的。
二、前置知识
一般情况下数据包在进入检测引擎之前都需要进行预处理,因为传入的数据包是分片的需要重组,然后HTTP请求的URL字符串需要同一格式化,一些可疑的行为需要探测等等。如果单纯依靠规则匹配,很难完成这些工作,所以snort就引入了分片重组,BO后门检测等等预处理功能。
snort功能十分强大,但是其本身的功能其实非常简单,就是嗅探数据包。那么这些丰富的功能是怎么实现的呢?snort采用了插件的机制拓展其本身的功能,各种各样丰富的插件造就了snort的功能强大。
所以我们接下来要分析的数据包预处理模块也是利用各种预处理插件实现的,因此我们对数据包预处理模块的源码分析,实际上是对预处理插件源码以及snort与插件交互的源码的分析。
三、源码分析树状图
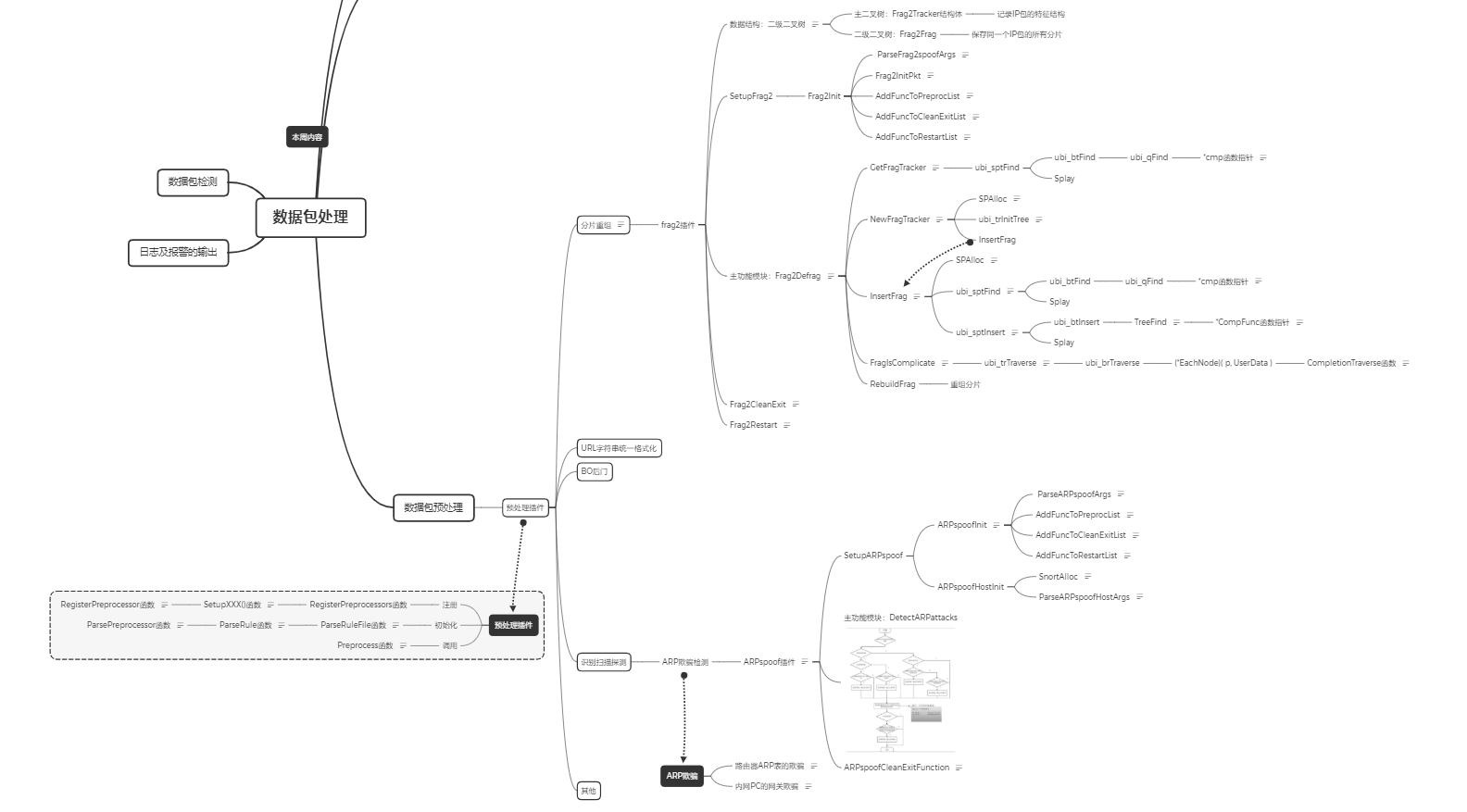
以上是我对snort数据包预处理模块源码分析的流程及其大概实现思路流程图,接下去我将会逐部分描述这张树状图,以分析snort源码。
四、预处理插件的基本工作流程

如上图,预处理插件主要分为三部分,注册、初始化和调用。
首先是注册,snort里会先调用一个InitPreprocessors()函数对所有预处理插件进行初始化,其实这个函数并没有实现本质的功能只是人为的将许多SetupXXX()函数组合在一起,这里的XXX表示不同的预处理插件的具体插件名。
InitPreprocessors()函数源码如下:
void InitPreprocessors()
{
if(!pv.quiet_flag)
{
LogMessage("Initializing Preprocessors!\n");
}
SetupPortscan();
SetupPortscanIgnoreHosts();
SetupRpcDecode();
SetupBo();
SetupTelNeg();
SetupStream4();
SetupFrag2();
SetupARPspoof();
SetupConv();
SetupScan2();
SetupHttpInspect();
SetupPerfMonitor();
SetupFlow();
}
SetupFrag2()函数源码如下:
void SetupFrag2()
{
RegisterPreprocessor("frag2", Frag2Init);
DEBUG_WRAP(DebugMessage(DEBUG_FRAG2, "Preprocessor: frag2 is setup...\n"););
}
然后InitPreprocessors()函数会根据不同的插件名,调用不同的SetupXXX()函数,在SetupXXX()函数中会调用RegisterPreprocessor()函数进行实际的注册操作。将对应插件的插件名和对应的初始化函数进行封装,并通过一个PreprocessNode节点指向它,将其链入到PreprocessorKeywordlist链表中,以便之后的遍历使用。
需要注意的是,在InitPreprocessors()函数中只是进行了注册,并没有进行初始化,而是将初始化函数封装了起来。因为snort中插件有很多,但是并不一定全部会用到,所以如果一开始就对所有的插件进行初始化就会导致程序的效率降低。因此snort将初始化推迟到调用的之前,只有我们用到了这个插件,才会对其进行初始化,并且采用了注册的机制,方便快速的找到对应的插件名和对应的初始化函数。
初始化的具体流程:
snort允许用户在snort.conf文件中对预处理插件进行配置,所以程序必须从snort.conf将配置信息读取出来,分析参数传给对应的预处理插件。
所以一开始主函数会调用ParseRuleFile()函数用于将snort.conf文件中的配置一行行的读取出来并交由ParseRule()函数解析和拆分。
ParseRule()函数会分析每一行的配置,判断配置的类型,如果是预处理插件配置会交给ParsePreprocessor()函数进一步分析配置参数。
ParsePreprocessor()函数会取出配置文件中预处理插件的插件名关键字,然后遍历PreprocessorKeywordlist链表找到对应的节点,并把配置参数交给对应的初始化参数来完成。
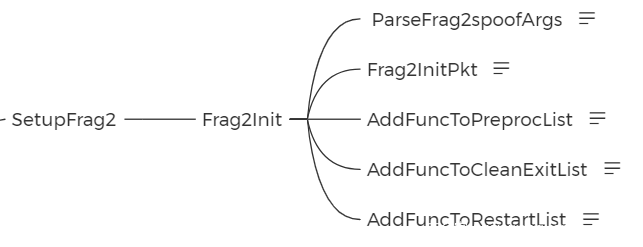
在初始化函数中还会三个AddFuncToXXXlist()函数,用于将不同的作用的函数添加到不同的链表中。比如AddFuncToPreprocList()函数就是将实现插件主功能函数添加到Preprocess链表中去,便于之后的调用。后面两个AddFuncToXXXlist()函数也是同理,根据字面意思就可以理解。
在初始化函数中已经将插件的主功能函数添加到了Preprocess链表中,所以会调用Preprocess()函数进行调用。不同的插件实现方式不同,之后会详细举例进行分析。
五、分片重组——Frag2插件分析
因为不同的网络硬件设备往往有一个最大传输单元(MTU),以太网的MTU为1500字节,而IP包的大小最大为0xFFFF字节,所以大于1500字节的IP包会被分片,到对端重组。这个过程中可能攻击者将特征匹配字符拆开绕过IDS的检测,比如将”ABC”拆成”A”、”B”、”C”传输 。所以为了更好的提高snort的检测性能,snort在进行检测之前会将数据包进行重组,以防止分片攻击的发生。

如果陆续有100个分片进入snort,就会出现以下情况:1、100个分片中有多个数据包。2、每个数据包有多个分片。
为了清楚的分出属于同一IP包的不同分片,需要采用至少二维的结构。snort采用了二级二叉树。主二叉树用于记录数据包的特征,然后二级二叉树用于记录这个数据包下的所有分片包。主二叉树每一个节点都指向一个FragTracker结构,结构如下所示:
typedef struct _FragTracker
{
ubi_trNode Node; /*二叉树结点*/
u_int32_t sip; /* src IP */
u_int32_t dip; /* dst IP */
u_int16_t id; /* IP ID */
u_int8_t protocol; /* IP protocol */
u_int8_t ttl; /* ttl used to detect evasions */
u_int8_t alerted;
u_int32_t frag_flags;
u_int32_t last_frag_time;
u_int32_t frag_bytes;
u_int32_t calculated_size;
u_int32_t frag_pkts;
ubi_trRoot fraglist; /*二级二叉树根节点*/
ubi_trRootPtr fraglistPtr; /*指向二级二叉树根节点的指针*/
} FragTracker;
Frag2会对新来的分片包在主二叉树中进行匹配,如果找到了匹配的节点,那么这个分片包就是这个节点对应数据包的后续分片包,就会被加入到该节点的二级二叉树中。如果不匹配,那说明这个分片包来自一个全新的数据包,就会给这个分片包分配一个全新的主二叉树节点,并把这个分片包作为第一个分片加入。同时程序会判断二级二叉树是否已经接收所有的分片包,如果是则会对数据包进行重组。
首先是初始化,这个过程和上面说的一样,这里就不重复了。


FragTracker *GetFragTracker(Packet *p)
{
FragTracker ft;
FragTracker *returned;
if(ubi_trCount(FragRootPtr) == 0)
return NULL;
if(f2data.frag_sp_data.mem_usage == 0)
{
DEBUG_WRAP(DebugMessage(DEBUG_FRAG2, "trCount says nodes exist but "
"f2data.frag_sp_data.mem_usage = 0\n"););
return NULL;
}
ft.sip = p->iph->ip_src.s_addr;
ft.dip = p->iph->ip_dst.s_addr;
ft.id = p->iph->ip_id;
ft.protocol = p->iph->ip_proto;
returned = (FragTracker *) ubi_sptFind(FragRootPtr, (ubi_btItemPtr)&ft);
DEBUG_WRAP(DebugMessage(DEBUG_FRAG2, "returning %p\n", returned););
return returned;
}
检测分片包的特征(IP地址、上层协议、ID值等),在主二叉树中是否存在,存在则返回fragtracker变量 。这个函数其实是通过ubi_sptFind函数实现的,而ubi_sptFind则是通过ubi_btFind函数实现的,ubi_btFind又调用了qFind函数实现,如下为qFind函数的源码:
static ubi_btNodePtr qFind( ubi_btCompFunc cmp,
ubi_btItemPtr FindMe,
register ubi_btNodePtr p )
/* ------------------------------------------------------------------------ **
* This function performs a non-recursive search of a tree for a node
* matching a specific key. It is called "qFind()" because it is
* faster that TreeFind (below).
*
* Input:
* cmp - a pointer to the tree's comparison function.
* FindMe - a pointer to the key value for which to search.
* p - a pointer to the starting point of the search. <p>
* is considered to be the root of a subtree, and only
* the subtree will be searched.
*
* Output:
* A pointer to a node with a key that matches the key indicated by
* FindMe, or NULL if no such node was found.
*
* Note: In a tree that allows duplicates, the pointer returned *might
* not* point to the (sequentially) first occurance of the
* desired key.
* ------------------------------------------------------------------------ **
*/
{
int tmp;
while( (NULL != p)
&& ((tmp = ubi_trAbNormal( (*cmp)(FindMe, p) )) != ubi_trEQUAL) )
p = p->Link[tmp];
return( p );
} /* qFind */
可以看到qFind先是通过while循环遍历二叉树,而p->link是指向下一个节点的,但是到底是指向左节点、右节点还是父节点是通过tmp的值传递的,而tmp的值是通过cmp函数指针获得的,cmp函数指针指向的是一个CompareFunc函数,通过这个函数判断节点是否匹配,返回相应的值,然后这个返回的值会被传到ubi_trAbNormal中,这是一个宏定义,源码如下:
#define ubi_trAbNormal(W) ((char)( ((char)ubi_btSgn( (long)(W) )) \
+ ubi_trEQUAL ))
里面又使用了ubi_btSgn函数,源码如下:
long ubi_btSgn( register long x )
/* ------------------------------------------------------------------------ **
* Return the sign of x; {negative,zero,positive} ==> {-1, 0, 1}.
*
* Input: x - a signed long integer value.
*
* Output: the "sign" of x, represented as follows:
* -1 == negative
* 0 == zero (no sign)
* 1 == positive
*
* Note: This utility is provided in order to facilitate the conversion
* of C comparison function return values into BinTree direction
* values: {LEFT, PARENT, EQUAL}. It is INCORPORATED into the
* ubi_trAbNormal() conversion macro!
*
* ------------------------------------------------------------------------ **
*/
{
return( (x)?((x>0)?(1):(-1)):(0) );
} /* ubi_btSgn */
正如注释所说-1、1、0代表二叉树的不同节点,然后tmp根据宏处理之后的结果,决定主二叉树下一个是哪个节点。

如果在主二叉树中没有找到匹配的,说明这个分片包是一个全新的数据包,就会调用这个函数在主二叉树上创建一个全新的节点。
该函数会先调用SPAlloc函数用于在主二叉树上分配一个二叉树节点,并将这个数据包的地址、协议、ID等特征信息赋给Frag2Tracker结构体中对应的变量。然后会调用ubi_trInitTree函数,这个函数会 初始化ubi_btRoot结构,这个结构里有RootPtr->cmp=CompFunc,在GetFragTracker里应该会用到 。
当主二叉树的节点建立完之后,需要将分片包插入到对应的二级二叉树中,这时就需要使用InsertFrag()函数。
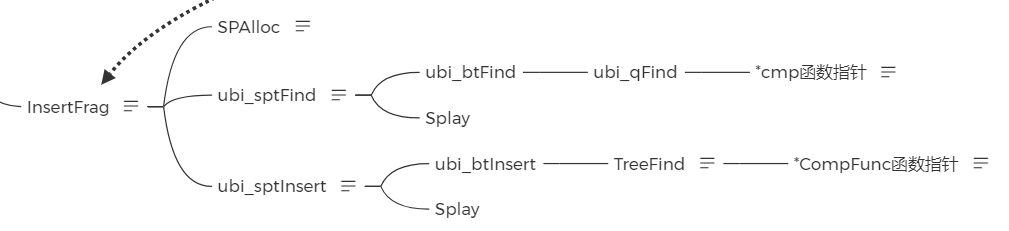
InsertFrag()函数首先调用SPAlloc()函数申请一个新的节点,然后会使用ubi_sptFind()函数查找二级二叉树中当前的分片包是否已经存在,如果不存在就会调用ubi_sptInsert()函数将其插入二级二叉树中,而ubi_sptInsert()函数实际上是通过ubi_btInsert()函数实际执行的,声明源码如下:
ubi_trBool ubi_btInsert( ubi_btRootPtr RootPtr,
ubi_btNodePtr NewNode,
ubi_btItemPtr ItemPtr,
ubi_btNodePtr *OldNode );
部分重要源码:
/* Find a place for the new node. */
*OldNode = TreeFind(ItemPtr, (RootPtr->root), &parent, &tmp, (RootPtr->cmp));
/* Now add the node to the tree... */
if( NULL == (*OldNode) ) /* The easy one: we have a space for a new node! */
{
if( NULL == parent )
RootPtr->root = NewNode; /*作为根节点插入*/
else
{
parent->Link[(int)tmp] = NewNode; /*插入新节点*/
NewNode->Link[ubi_trPARENT] = parent; /*指回父节点*/
NewNode->gender = tmp;
}
(RootPtr->count)++;
return( ubi_trTRUE );
}
通过TreeFind()函数遍历二叉树找到找到下一节点为空的节点,然后将新的节点插入。TreeFind()函数的实现和qFind()函数基本一致,就不重复了。
FragIsComplicate()函数和RebuildFrag()函数

FragIsComplicate()函数主要是用来检查二级二叉树是不是已经接收了所有的分片包。这个函数过程中最重要的就是对二叉树的遍历,而这个遍历过程的函数调用流程可以从以上的树状图中可以看出。先是调用了ubi_trTraverse,这是一个宏定义,源码如下:
#define ubi_trTraverse( Rp, En, Ud ) \
ubi_btTraverse((ubi_btRootPtr)(Rp), (ubi_btActionRtn)(En), (void *)(Ud))
本质上是调用了ubi_btTraverse()函数,源码如下:
unsigned long ubi_btTraverse( ubi_btRootPtr RootPtr,
ubi_btActionRtn EachNode,
void *UserData )
/* ------------------------------------------------------------------------ **
* Traverse a tree in sorted order (non-recursively). At each node, call
* (*EachNode)(), passing a pointer to the current node, and UserData as the
* second parameter.
*
* Input: RootPtr - a pointer to an ubi_btRoot structure that indicates
* the tree to be traversed.
* EachNode - a pointer to a function to be called at each node
* as the node is visited.
* UserData - a generic pointer that may point to anything that
* you choose.
*
* Output: A count of the number of nodes visited. This will be zero
* if the tree is empty.
*
* ------------------------------------------------------------------------ **
*/
{
ubi_btNodePtr p = ubi_btFirst( RootPtr->root );
unsigned long count = 0;
while( NULL != p )
{
(*EachNode)( p, UserData );
count++;
if(RootPtr->count != 0)
p = ubi_btNext( p );
else
return count;
}
return( count );
} /* ubi_btTraverse */
(*EachNode)( p, UserData );这句是关键,但是直接看这个函数中的这句会发现中间的这些参数都是形参,不方便理解,所以我们找到FragIsComplicate()函数中传入的参数。
(void)ubi_trTraverse(ft->fraglistPtr, CompletionTraverse, compdata);
(*EachNode)是一个函数指针,而我们传入的函数时CompletionTraverse()函数,所以这句话相当于时调用了CompletionTraverse()函数来检验每个分片包的偏移量,来判断所有分片是否已经完整。
CompletionTraverse()函数源码如下:
static void CompletionTraverse(ubi_trNodePtr NodePtr, void *complete)
{
Frag2Frag *frag;
CompletionData *comp = (CompletionData *) complete;
frag = (Frag2Frag *) NodePtr;
if(frag->offset == next_offset) /*next_offset全局变量用于记录当前偏移地址值*/
{
next_offset = frag->offset + frag->size; /*更新next_offset*/
}
else if(frag->offset < next_offset) /*当前offset和之前的offset重叠,发生teardrop攻击*/
{
/* flag a teardrop attack detection */
comp->teardrop = 1;
if(frag->size + frag->offset > next_offset)
{
next_offset = frag->offset + frag->size;
}
}
else if(frag->offset > next_offset) /*当前分片与前一片存在空白,分片数据还不完整*/
{
DEBUG_WRAP(DebugMessage(DEBUG_FRAG2, "Holes in completion check... (%u > %u)\n",
frag->offset, next_offset););
comp->complete = 0; /*不完整不能重组*/
}
return;
}
当Frag2IsComplicate()所有的分片包都已经收集的时候,就会调用RebuildFrag()函数对数据包进行重组。
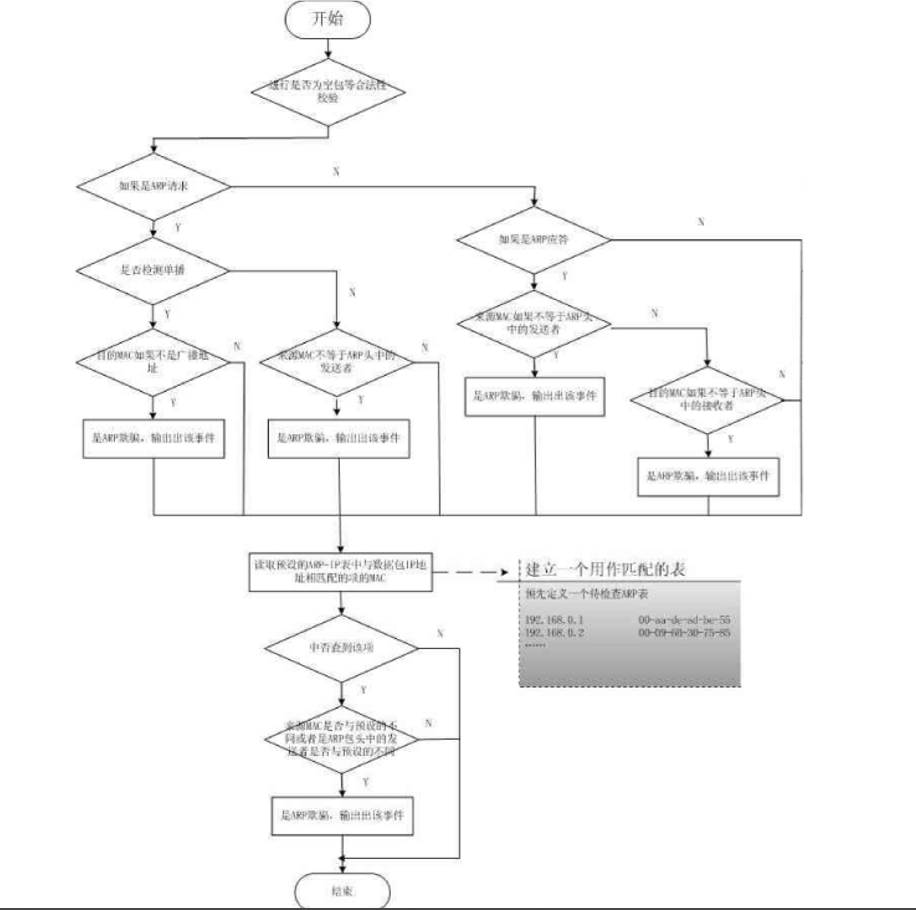
六、ARP欺骗检测插件——ARPspoof插件分析
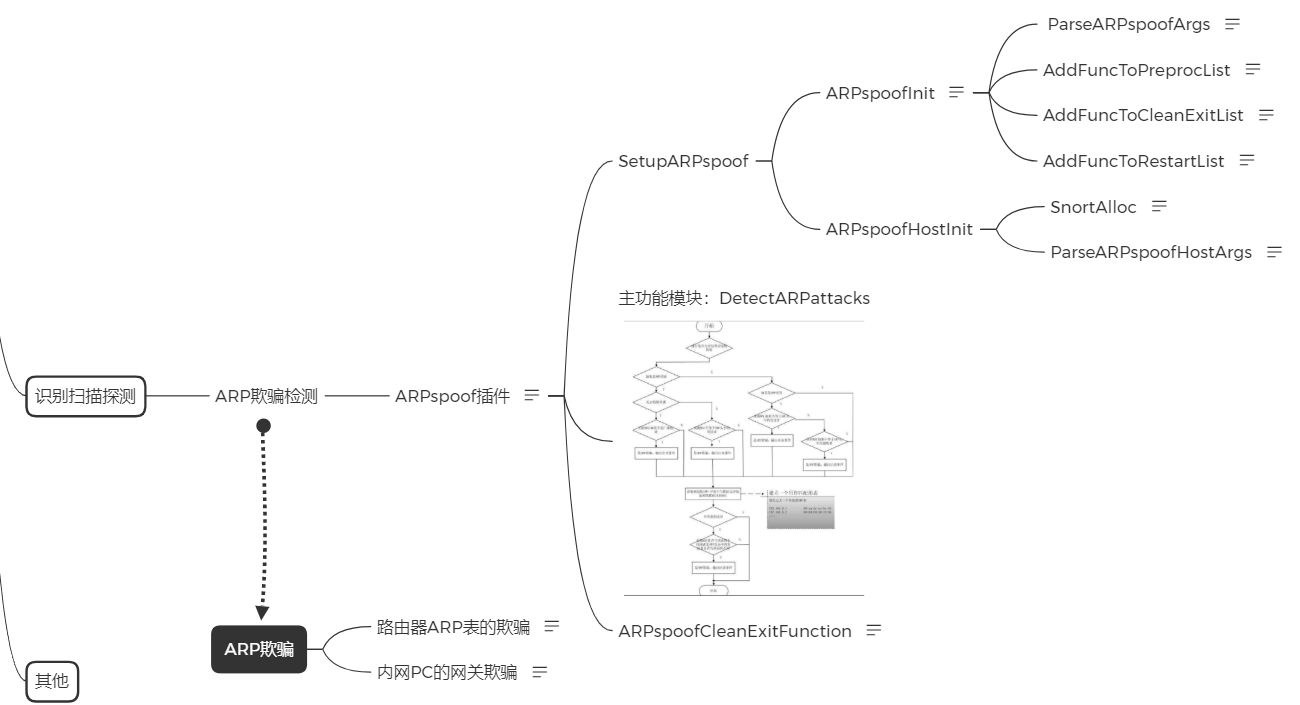
插件大体的流程和Frag2插件流程类似,就整体粗略的分析一下,可以按照上述Frag2插件类似的分析方法对该插件进行分析。
也是有一个Setup函数用于该插件的初始化,里面又分成两个部分,Init和HostInit函数,Init函数就是常规的初始化,而HostInit函数则是用于读取snort.conf配置文件中的MAC-IP对照表。
然后这个插件的主功能函数模块时DetectARPattacks()函数,这里借用《Snort入侵检测系统源码分析—独孤九贱》书中的流程图解释:
参考资料:
《Snort入侵检测系统源码分析—独孤九贱》